 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Aggregation Networks for Segmentation of Multi-Gigapixel Histology Images
Paper and Code
Jul 27, 2017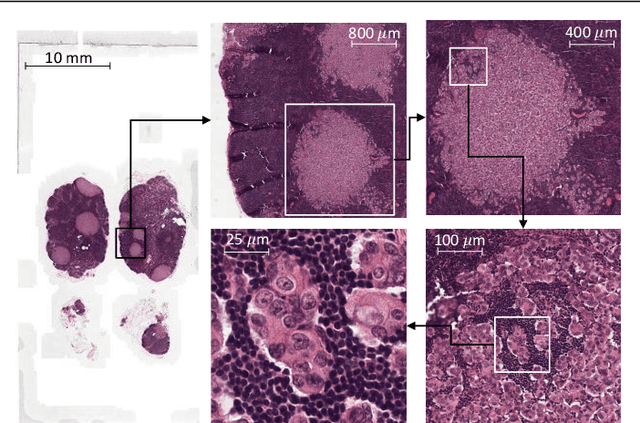
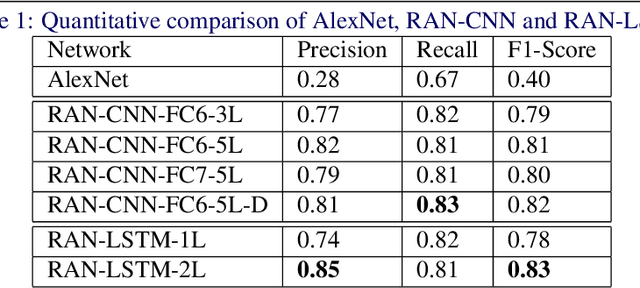
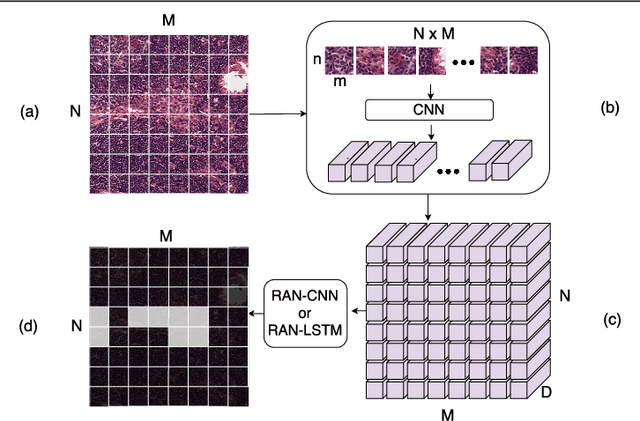
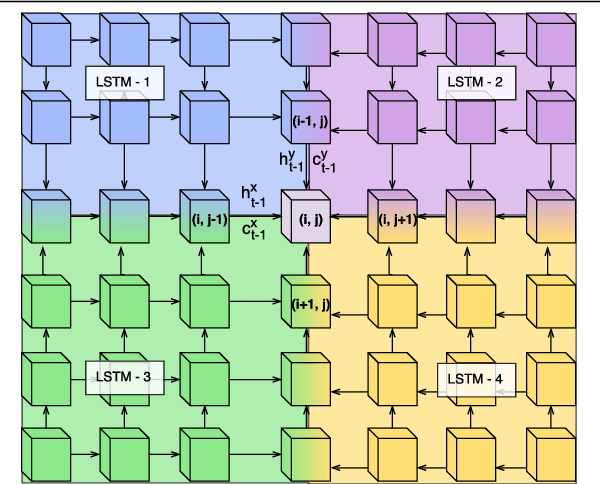
Convolutional Neural Network (CNN) models have become the state-of-the-art for most computer vision tasks with natural images. However, these are not best suited for multi-gigapixel resolution Whole Slide Images (WSIs) of histology slides due to large size of these images. Current approaches construct smaller patches from WSIs which results in the loss of contextual information. We propose to capture the spatial context using novel Representation-Aggregation Network (RAN) for segmentation purposes, wherein the first network learns patch-level representation and the second network aggregates context from a grid of neighbouring patches. We can use any CNN for representation learning, and can utilize CNN or 2D-Long Short Term Memory (2D-LSTM) for context-aggregation. Our method significantly outperformed conventional patch-based CNN approaches on segmentation of tumour in WSIs of breast cancer tissue sections.