 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Offline Model-based Optimization for Industrial Process Control
Paper and Code
May 15, 2022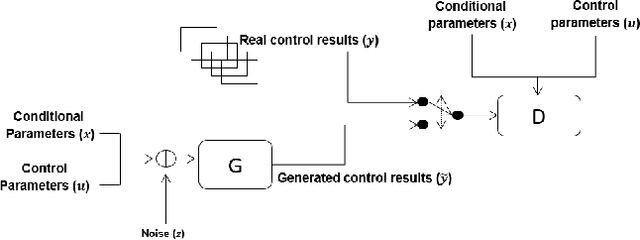
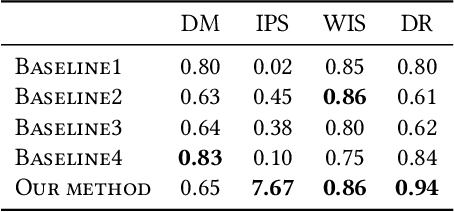
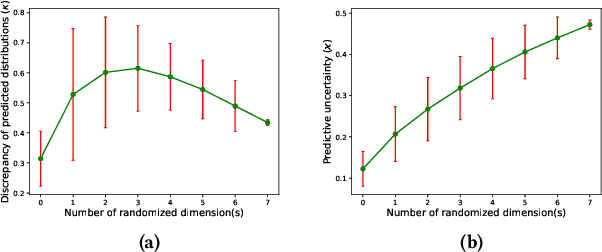

In the research area of offline model-based optimization, novel and promising methods are frequently developed. However, implementing such methods in real-world industrial systems such as production lines for process control is oftentimes a frustrating process. In this work, we address two important problems to extend the current success of offline model-based optimization to industrial process control problems: 1) how to learn a reliable dynamics model from offline data for industrial processes? 2) how to learn a reliable but not over-conservative control policy from offline data by utilizing existing model-based optimization algorithms? Specifically, we propose a dynamics model based on ensemble of conditional generative adversarial networks to achieve accurate reward calculation in industrial scenarios. Furthermore, we propose an epistemic-uncertainty-penalized reward evaluation function which can effectively avoid giving over-estimated rewards to out-of-distribution inputs during the learning/searching of the optimal control policy. We provide extensive experiments with the proposed method on two representative cases (a discrete control case and a continuous control case), showing that our method compares favorably to several baselines in offline policy learning for industrial process control.