 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelationship-Aware Spatial Perception Fusion for Realistic Scene Layout Generation
Paper and Code
Sep 02, 2019
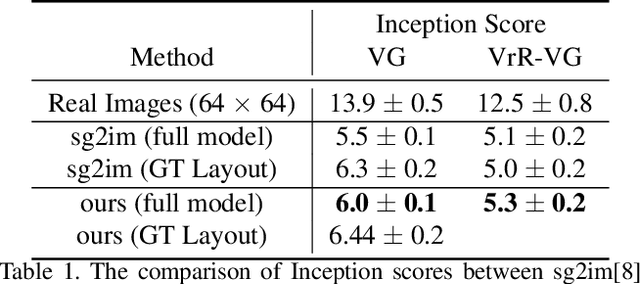

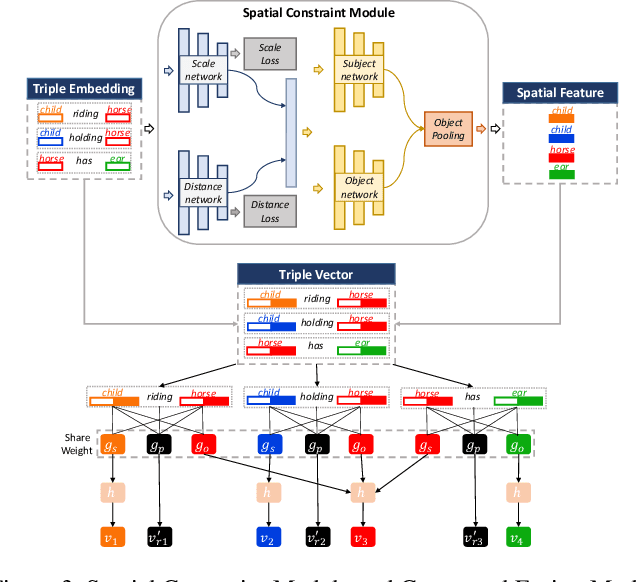
The significant progress on Generative Adversarial Networks (GANs) have made it possible to generate surprisingly realistic images for single object based on natural language descriptions. However, controlled generation of images for multiple entities with explicit interactions is still difficult to achieve due to the scene layout generation heavily suffer from the diversity object scaling and spatial locations. In this paper, we proposed a novel framework for generating realistic image layout from textual scene graphs. In our framework, a spatial constraint module is designed to fit reasonable scaling and spatial layout of object pairs with considering relationship between them. Moreover, a contextual fusion module is introduced for fusing pair-wise spatial information in terms of object dependency in scene graph. By using these two modules, our proposed framework tends to generate more commonsense layout which is helpful for realistic image generation. Experimental results including quantitative results, qualitative results and user studies on two different scene graph datasets demonstrate our proposed framework's ability to generate complex and logical layout with multiple objects from scene graph.