 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Partially Known World Dynamics
Paper and Code
Dec 12, 2012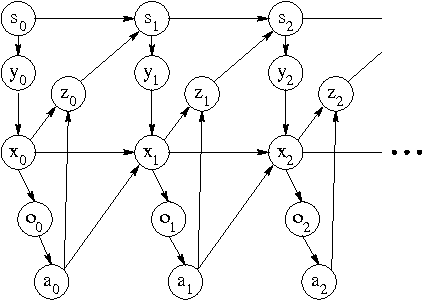

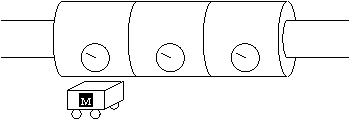
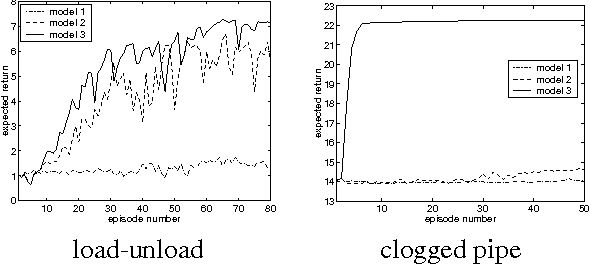
Reinforcement learning would enjoy better success on real-world problems if domain knowledge could be imparted to the algorithm by the modelers. Most problems have both hidden state and unknown dynamics. Partially observable Markov decision processes (POMDPs) allow for the modeling of both. Unfortunately, they do not provide a natural framework in which to specify knowledge about the domain dynamics. The designer must either admit to knowing nothing about the dynamics or completely specify the dynamics (thereby turning it into a planning problem). We propose a new framework called a partially known Markov decision process (PKMDP) which allows the designer to specify known dynamics while still leaving portions of the environment s dynamics unknown.The model represents NOT ONLY the environment dynamics but also the agents knowledge of the dynamics. We present a reinforcement learning algorithm for this model based on importance sampling. The algorithm incorporates planning based on the known dynamics and learning about the unknown dynamics. Our results clearly demonstrate the ability to add domain knowledge and the resulting benefits for learning.