 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Feedback-modulated TD-STDP
Paper and Code
Aug 29, 2020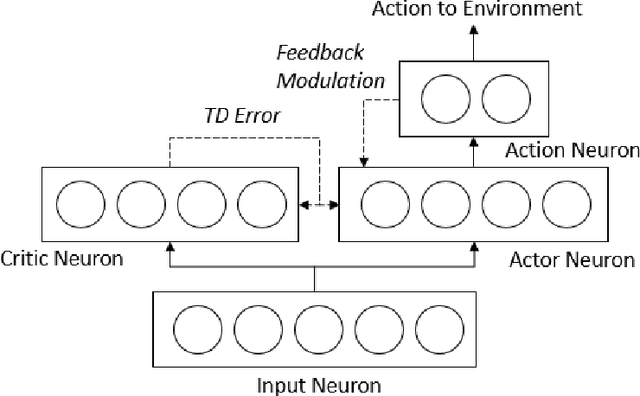


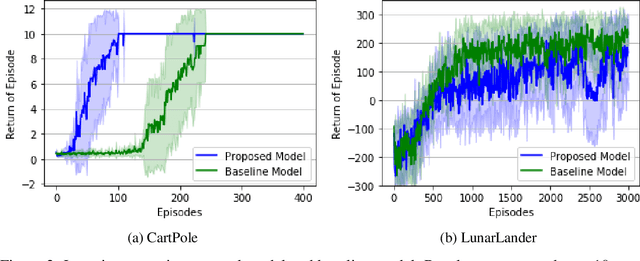
Spiking neuron networks have been used successfully to solve simple reinforcement learning tasks with continuous action set applying learning rules based on spike-timing-dependent plasticity (STDP). However, most of these models cannot be applied to reinforcement learning tasks with discrete action set since they assume that the selected action is a deterministic function of firing rate of neurons, which is continuous. In this paper, we propose a new STDP-based learning rule for spiking neuron networks which contains feedback modulation. We show that the STDP-based learning rule can be used to solve reinforcement learning tasks with discrete action set at a speed similar to standard reinforcement learning algorithms when applied to the CartPole and LunarLander tasks. Moreover, we demonstrate that the agent is unable to solve these tasks if feedback modulation is omitted from the learning rule. We conclude that feedback modulation allows better credit assignment when only the units contributing to the executed action and TD error participate in learning.