 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning in the Wild: Scalable RL Dispatching Algorithm Deployed in Ridehailing Marketplace
Paper and Code
Feb 10, 2022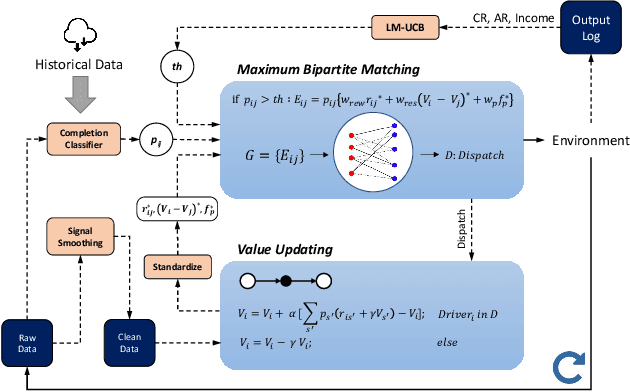
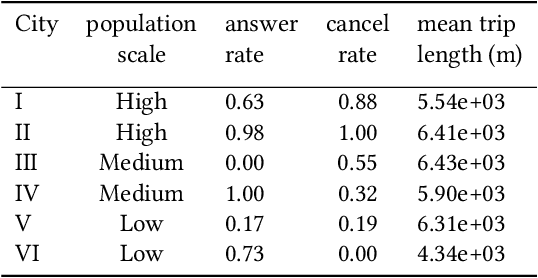
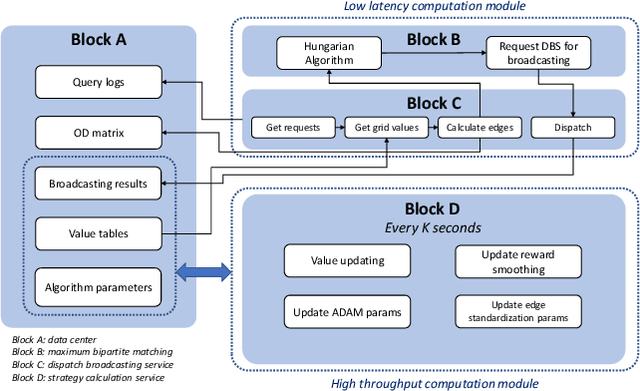
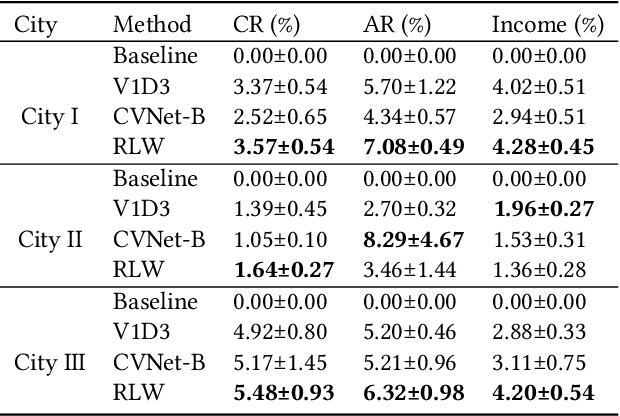
In this study, a real-time dispatching algorithm based on reinforcement learning is proposed and for the first time, is deployed in large scale. Current dispatching methods in ridehailing platforms are dominantly based on myopic or rule-based non-myopic approaches. Reinforcement learning enables dispatching policies that are informed of historical data and able to employ the learned information to optimize returns of expected future trajectories. Previous studies in this field yielded promising results, yet have left room for further improvements in terms of performance gain, self-dependency, transferability, and scalable deployment mechanisms. The present study proposes a standalone RL-based dispatching solution that is equipped with multiple mechanisms to ensure robust and efficient on-policy learning and inference while being adaptable for full-scale deployment. A new form of value updating based on temporal difference is proposed that is more adapted to the inherent uncertainty of the problem. For the driver-order assignment, a customized utility function is proposed that when tuned based on the statistics of the market, results in remarkable performance improvement and interpretability. In addition, for reducing the risk of cancellation after drivers' assignment, an adaptive graph pruning strategy based on the multi-arm bandit problem is introduced. The method is evaluated using offline simulation with real data and yields notable performance improvement. In addition, the algorithm is deployed online in multiple cities under DiDi's operation for A/B testing and is launched in one of the major international markets as the primary mode of dispatch. The deployed algorithm shows over 1.3% improvement in total driver income from A/B testing. In addition, by causal inference analysis, as much as 5.3% improvement in major performance metrics is detected after full-scale deployment.