 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization Learning Networks: Deep Learning for Tabular Datasets
Paper and Code
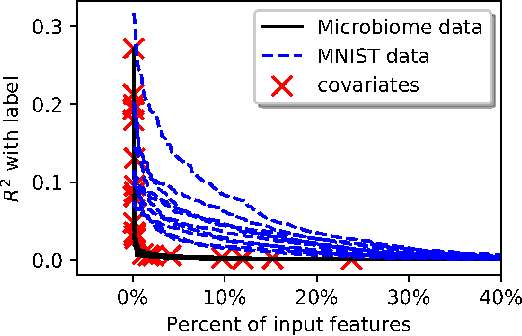

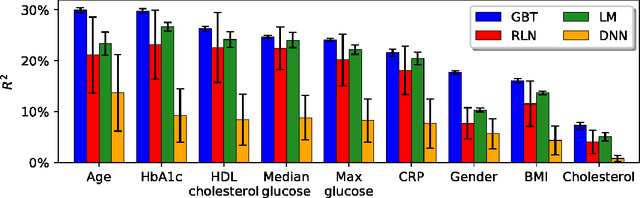
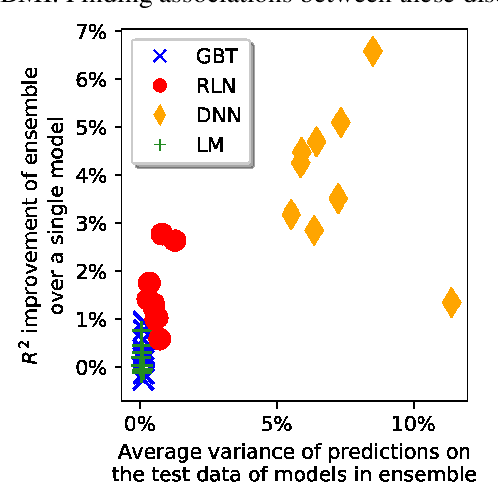
Despite their impressive performance, Deep Neural Networks (DNNs) typically underperform Gradient Boosting Trees (GBTs) on many tabular-dataset learning tasks. We propose that applying a different regularization coefficient to each weight might boost the performance of DNNs by allowing them to make more use of the more relevant inputs. However, this will lead to an intractable number of hyperparameters. Here, we introduce Regularization Learning Networks (RLNs), which overcome this challenge by introducing an efficient hyperparameter tuning scheme which minimizes a new Counterfactual Loss. Our results show that RLNs significantly improve DNNs on tabular datasets, and achieve comparable results to GBTs, with the best performance achieved with an ensemble that combines GBTs and RLNs. RLNs produce extremely sparse networks, eliminating up to 99.8% of the network edges and 82% of the input features, thus providing more interpretable models and reveal the importance that the network assigns to different inputs. RLNs could efficiently learn a single network in datasets that comprise both tabular and unstructured data, such as in the setting of medical imaging accompanied by electronic health records. An open source implementation of RLN can be found at https://github.com/irashavitt/regularization_learning_networks.