 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization in neural network optimization via trimmed stochastic gradient descent with noisy label
Paper and Code
Dec 21, 2020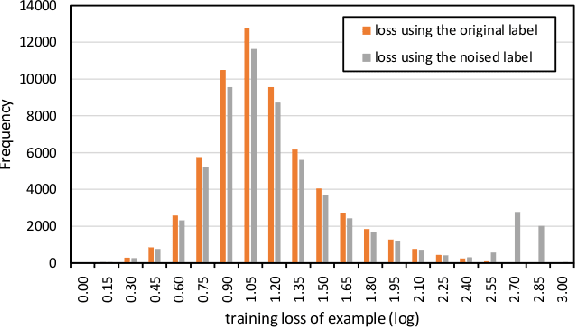
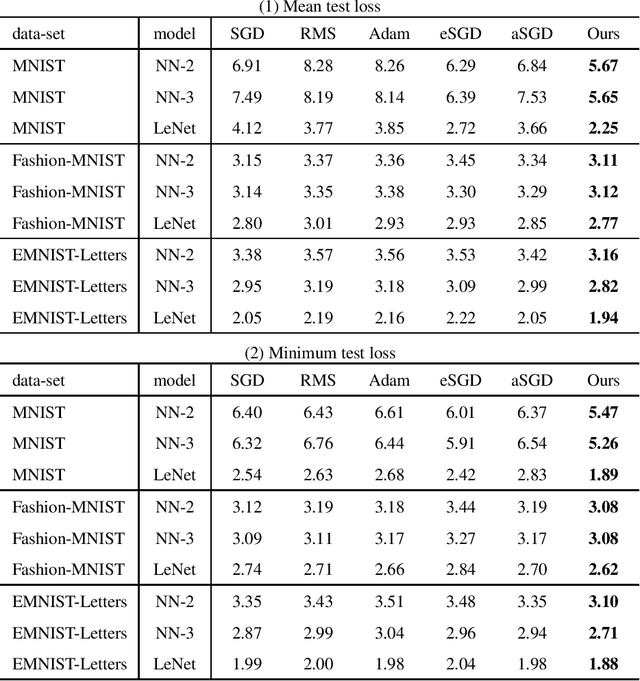
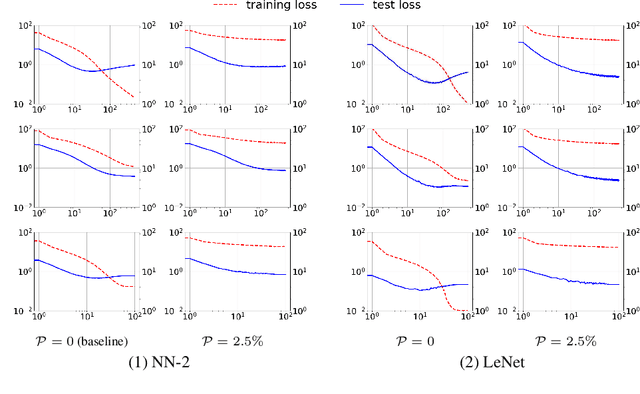
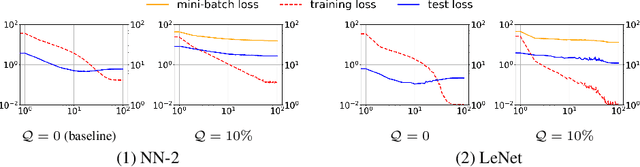
Regularization is essential for avoiding over-fitting to training data in neural network optimization, leading to better generalization of the trained networks. The label noise provides a strong implicit regularization by replacing the target ground truth labels of training examples by uniform random labels. However, it may also cause undesirable misleading gradients due to the large loss associated with incorrect labels. We propose a first-order optimization method (Label-Noised Trim-SGD) which combines the label noise with the example trimming in order to remove the outliers. The proposed algorithm enables us to impose a large label noise and obtain a better regularization effect than the original methods. The quantitative analysis is performed by comparing the behavior of the label noise, the example trimming, and the proposed algorithm. We also present empirical results that demonstrate the effectiveness of our algorithm using the major benchmarks and the fundamental networks, where our method has successfully outperformed the state-of-the-art optimization methods.