 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGTR: End-to-end Point Cloud Correspondences with Transformers
Paper and Code
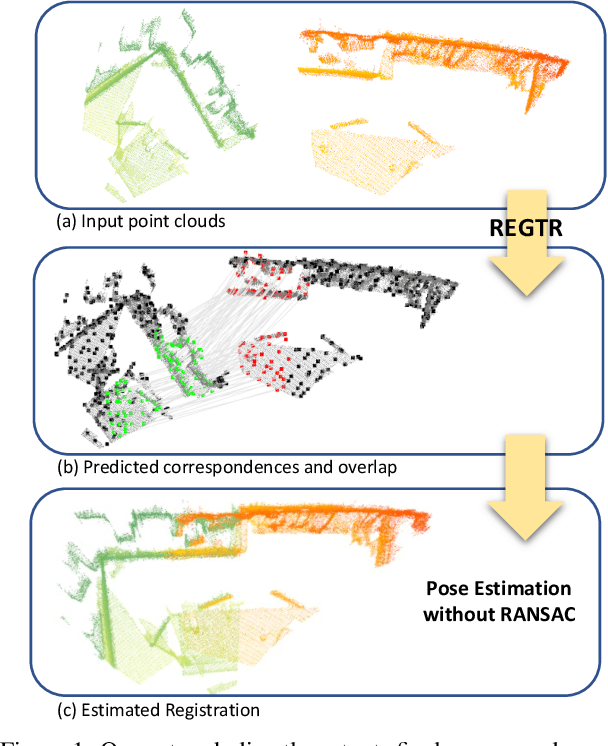

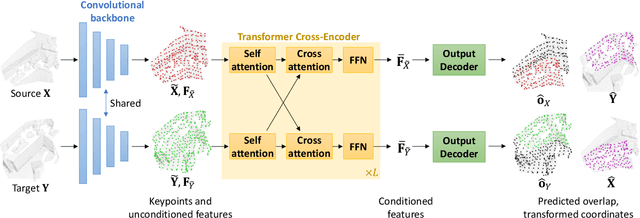
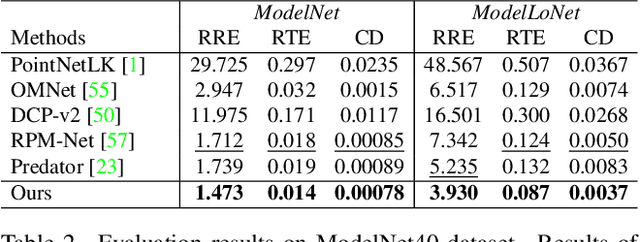
Despite recent success in incorporating learning into point cloud registration, many works focus on learning feature descriptors and continue to rely on nearest-neighbor feature matching and outlier filtering through RANSAC to obtain the final set of correspondences for pose estimation. In this work, we conjecture that attention mechanisms can replace the role of explicit feature matching and RANSAC, and thus propose an end-to-end framework to directly predict the final set of correspondences. We use a network architecture consisting primarily of transformer layers containing self and cross attentions, and train it to predict the probability each point lies in the overlapping region and its corresponding position in the other point cloud. The required rigid transformation can then be estimated directly from the predicted correspondences without further post-processing. Despite its simplicity, our approach achieves state-of-the-art performance on 3DMatch and ModelNet benchmarks. Our source code can be found at https://github.com/yewzijian/RegTR .