 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret bounds for Narendra-Shapiro bandit algorithms
Paper and Code
Jan 16, 2016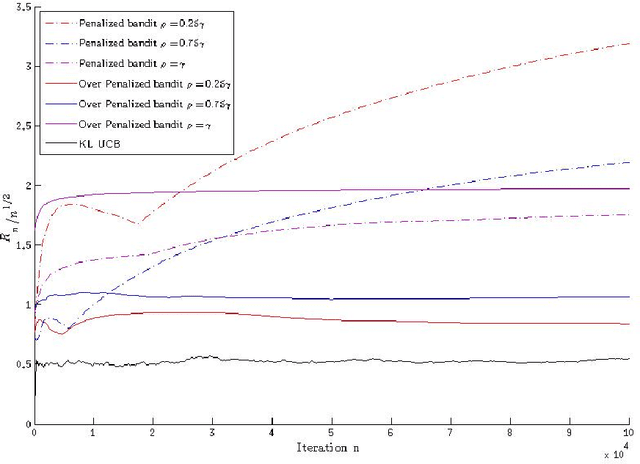

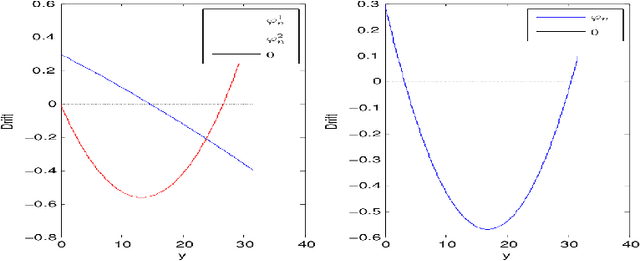
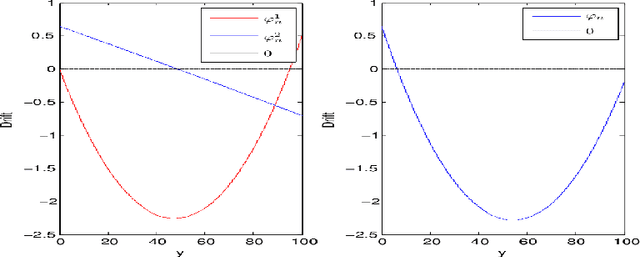
Narendra-Shapiro (NS) algorithms are bandit-type algorithms that have been introduced in the sixties (with a view to applications in Psychology or learning automata), whose convergence has been intensively studied in the stochastic algorithm literature. In this paper, we adress the following question: are the Narendra-Shapiro (NS) bandit algorithms competitive from a \textit{regret} point of view? In our main result, we show that some competitive bounds can be obtained for such algorithms in their penalized version (introduced in \cite{Lamberton_Pages}). More precisely, up to an over-penalization modification, the pseudo-regret $\bar{R}_n$ related to the penalized two-armed bandit algorithm is uniformly bounded by $C \sqrt{n}$ (where $C$ is made explicit in the paper). \noindent We also generalize existing convergence and rates of convergence results to the multi-armed case of the over-penalized bandit algorithm, including the convergence toward the invariant measure of a Piecewise Deterministic Markov Process (PDMP) after a suitable renormalization. Finally, ergodic properties of this PDMP are given in the multi-armed case.