 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret-Based Optimization for Robust Reinforcement Learning
Paper and Code


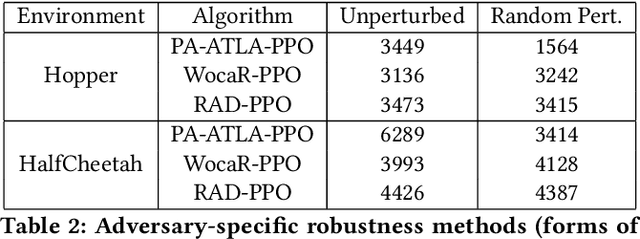

Deep Reinforcement Learning (DRL) policies have been shown to be vulnerable to small adversarial noise in observations. Such adversarial noise can have disastrous consequences in safety-critical environments. For instance, a self-driving car receiving adversarially perturbed sensory observations about nearby signs (e.g., a stop sign physically altered to be perceived as a speed limit sign) or objects (e.g., cars altered to be recognized as trees) can be fatal. Existing approaches for making RL algorithms robust to an observation-perturbing adversary have focused on reactive approaches that iteratively improve against adversarial examples generated at each iteration. While such approaches have been shown to provide improvements over regular RL methods, they are reactive and can fare significantly worse if certain categories of adversarial examples are not generated during training. To that end, we pursue a more proactive approach that relies on directly optimizing a well-studied robustness measure, regret instead of expected value. We provide a principled approach that minimizes maximum regret over a "neighborhood" of observations to the received "observation". Our regret criterion can be used to modify existing value- and policy-based Deep RL methods. We demonstrate that our approaches provide a significant improvement in performance across a wide variety of benchmarks against leading approaches for robust Deep RL.