 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Analysis of Distributed Online LQR Control for Unknown LTI Systems
Paper and Code
May 15, 2021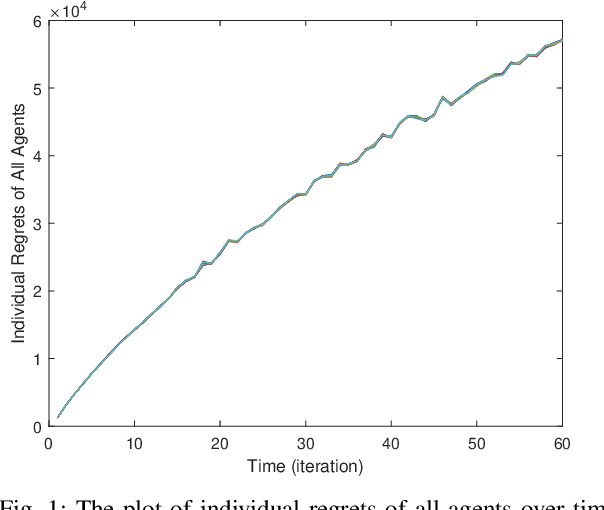
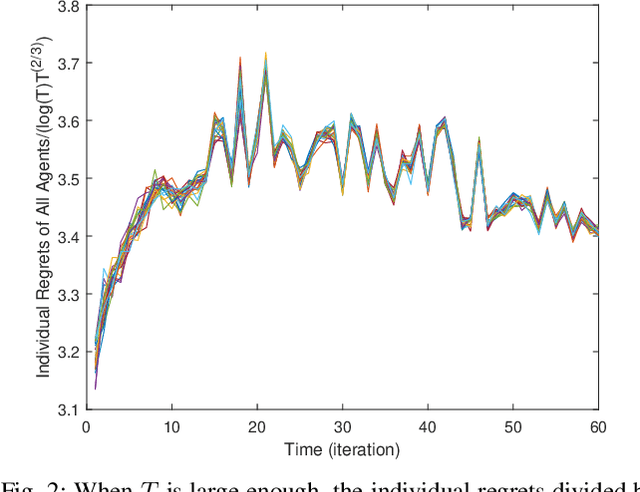
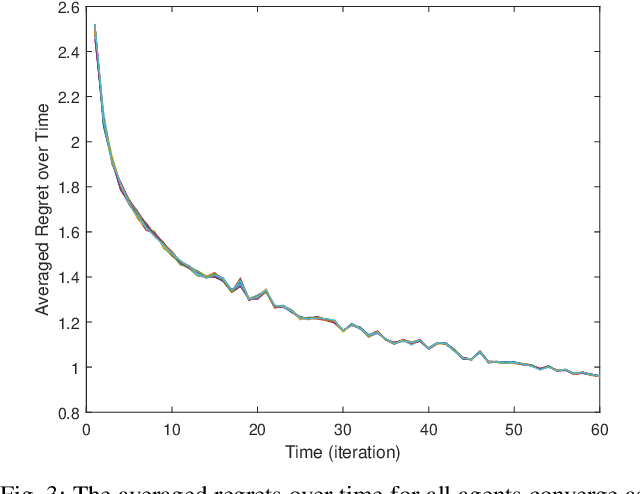
Online learning has recently opened avenues for rethinking classical optimal control beyond time-invariant cost metrics, and online controllers are designed when the performance criteria changes adversarially over time. Inspired by this line of research, we study the distributed online linear quadratic regulator (LQR) problem for linear time-invariant (LTI) systems with unknown dynamics. Consider a multi-agent network where each agent is modeled as a LTI system. The LTI systems are associated with time-varying quadratic costs that are revealed sequentially. The goal of the network is to collectively (i) estimate the unknown dynamics and (ii) compute local control sequences competitive to that of the best centralized policy in hindsight that minimizes the sum of costs for all agents. This problem is formulated as a {\it regret} minimization. We propose a distributed variant of the online LQR algorithm where each agent computes its system estimate during an exploration stage. The agent then applies distributed online gradient descent on a semi-definite programming (SDP) whose feasible set is based on the agent's system estimate. We prove that the regret bound of our proposed algorithm scales $\tilde{O}(T^{2/3})$, implying the consensus of the network over time. We also provide simulation results verifying our theoretical guarantee.