 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFIND: Retrieval-Augmented Factuality Hallucination Detection in Large Language Models
Paper and Code
Feb 19, 2025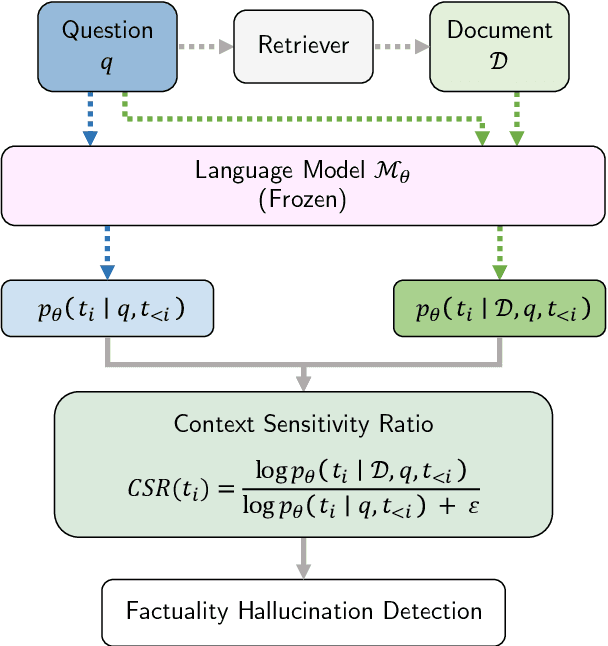


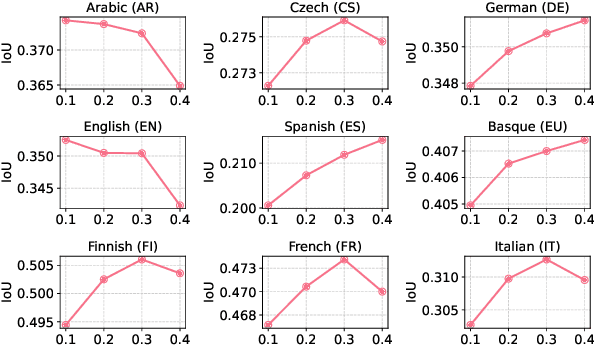
Hallucinations in large language model (LLM) outputs severely limit their reliability in knowledge-intensive tasks such as question answering. To address this challenge, we introduce REFIND (Retrieval-augmented Factuality hallucINation Detection), a novel framework that detects hallucinated spans within LLM outputs by directly leveraging retrieved documents. As part of the REFIND, we propose the Context Sensitivity Ratio (CSR), a novel metric that quantifies the sensitivity of LLM outputs to retrieved evidence. This innovative approach enables REFIND to efficiently and accurately detect hallucinations, setting it apart from existing methods. In the evaluation, REFIND demonstrated robustness across nine languages, including low-resource settings, and significantly outperformed baseline models, achieving superior IoU scores in identifying hallucinated spans. This work highlights the effectiveness of quantifying context sensitivity for hallucination detection, thereby paving the way for more reliable and trustworthy LLM applications across diverse languages.