 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Guided Texture and Structure Inference for Image Inpainting
Paper and Code

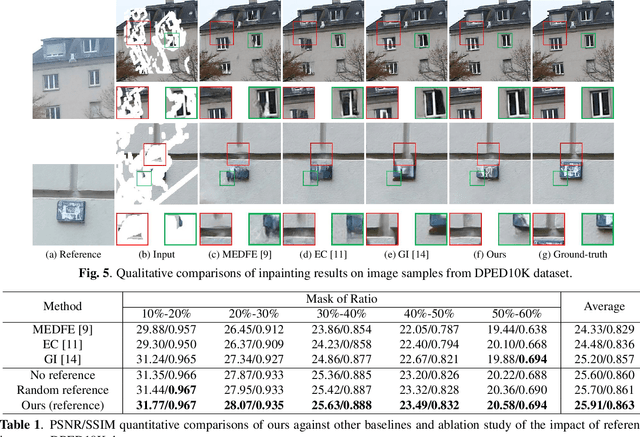

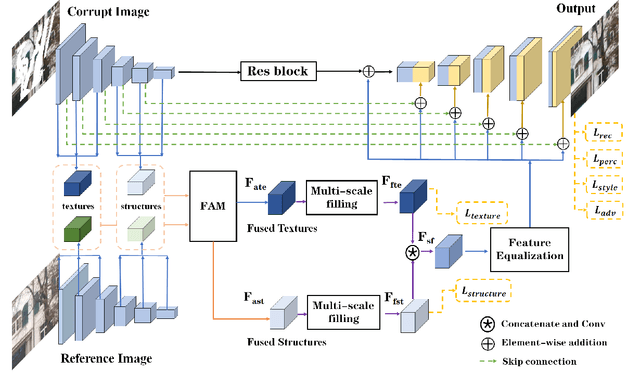
Existing learning-based image inpainting methods are still in challenge when facing complex semantic environments and diverse hole patterns. The prior information learned from the large scale training data is still insufficient for these situations. Reference images captured covering the same scenes share similar texture and structure priors with the corrupted images, which offers new prospects for the image inpainting tasks. Inspired by this, we first build a benchmark dataset containing 10K pairs of input and reference images for reference-guided inpainting. Then we adopt an encoder-decoder structure to separately infer the texture and structure features of the input image considering their pattern discrepancy of texture and structure during inpainting. A feature alignment module is further designed to refine these features of the input image with the guidance of a reference image. Both quantitative and qualitative evaluations demonstrate the superiority of our method over the state-of-the-art methods in terms of completing complex holes.