 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Planning Complexity of General Reinforcement Learning with Non-Markovian Abstractions
Paper and Code
Dec 26, 2021
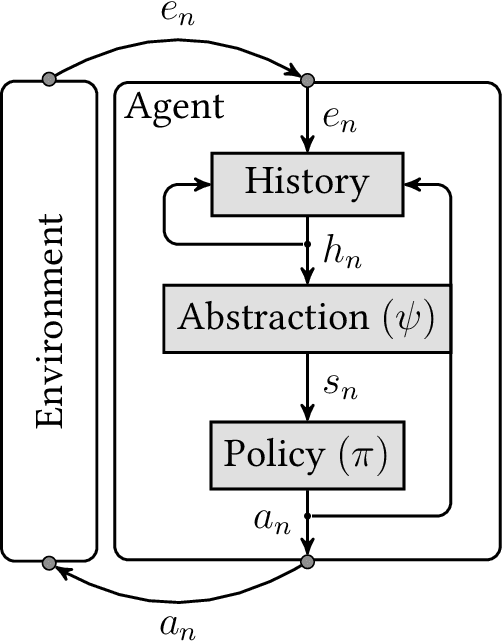
The field of General Reinforcement Learning (GRL) formulates the problem of sequential decision-making from ground up. The history of interaction constitutes a "ground" state of the system, which never repeats. On the one hand, this generality allows GRL to model almost every domain possible, e.g.\ Bandits, MDPs, POMDPs, PSRs, and history-based environments. On the other hand, in general, the near-optimal policies in GRL are functions of complete history, which hinders not only learning but also planning in GRL. The usual way around for the planning part is that the agent is given a Markovian abstraction of the underlying process. So, it can use any MDP planning algorithm to find a near-optimal policy. The Extreme State Aggregation (ESA) framework has extended this idea to non-Markovian abstractions without compromising on the possibility of planning through a (surrogate) MDP. A distinguishing feature of ESA is that it proves an upper bound of $O\left(\varepsilon^{-A} \cdot (1-\gamma)^{-2A}\right)$ on the number of states required for the surrogate MDP (where $A$ is the number of actions, $\gamma$ is the discount-factor, and $\varepsilon$ is the optimality-gap) which holds \emph{uniformly} for \emph{all} domains. While the possibility of a universal bound is quite remarkable, we show that this bound is very loose. We propose a novel non-MDP abstraction which allows for a much better upper bound of $O\left(\varepsilon^{-1} \cdot (1-\gamma)^{-2} \cdot A \cdot 2^{A}\right)$. Furthermore, we show that this bound can be improved further to $O\left(\varepsilon^{-1} \cdot (1-\gamma)^{-2} \cdot \log^3 A \right)$ by using an action-sequentialization method.