 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Model Jitter: Stable Re-training of Semantic Parsers in Production Environments
Paper and Code

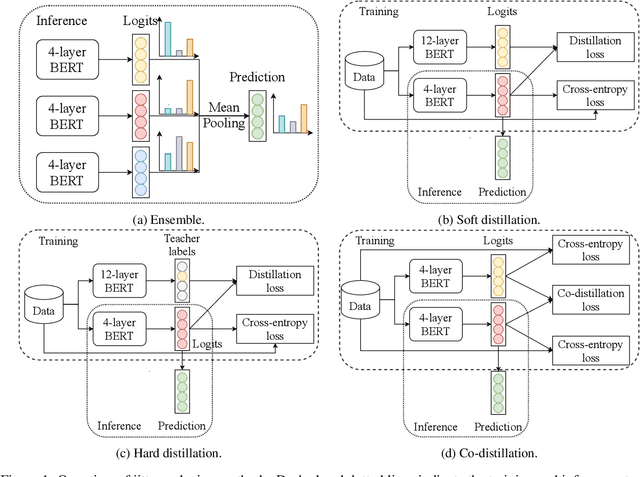
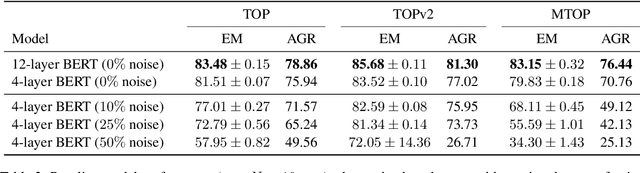
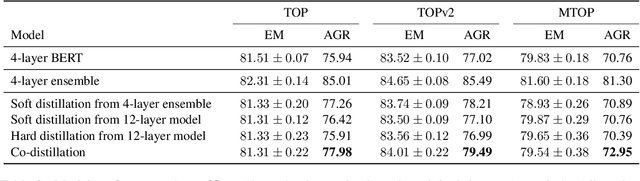
Retraining modern deep learning systems can lead to variations in model performance even when trained using the same data and hyper-parameters by simply using different random seeds. We call this phenomenon model jitter. This issue is often exacerbated in production settings, where models are retrained on noisy data. In this work we tackle the problem of stable retraining with a focus on conversational semantic parsers. We first quantify the model jitter problem by introducing the model agreement metric and showing the variation with dataset noise and model sizes. We then demonstrate the effectiveness of various jitter reduction techniques such as ensembling and distillation. Lastly, we discuss practical trade-offs between such techniques and show that co-distillation provides a sweet spot in terms of jitter reduction for semantic parsing systems with only a modest increase in resource usage.