 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedSync : Reducing Synchronization Traffic for Distributed Deep Learning
Paper and Code
Aug 13, 2018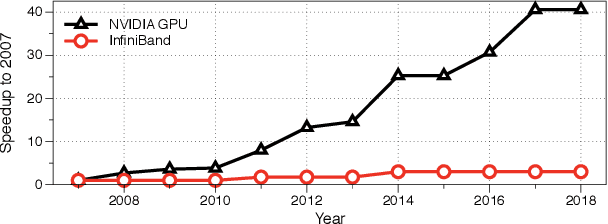
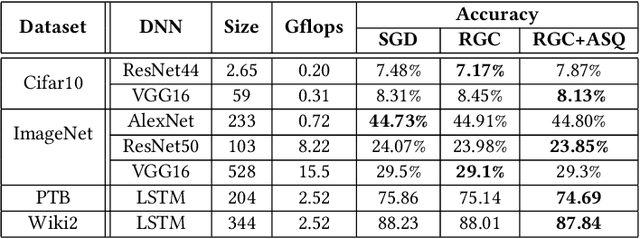
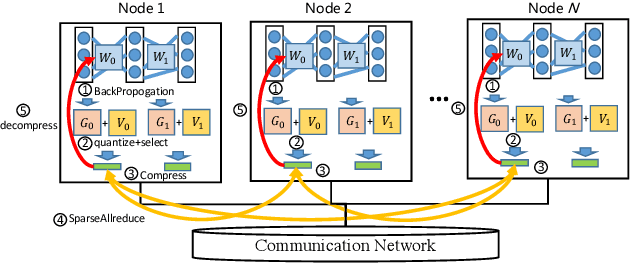
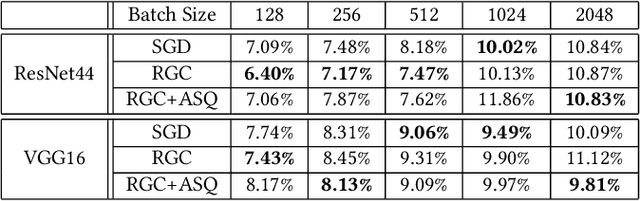
Data parallelism has already become a dominant method to scale Deep Neural Network (DNN) training to multiple computation nodes. Considering that the synchronization of local model or gradient between iterations can be a bottleneck for large-scale distributed training, compressing communication traffic has gained widespread attention recently. Among several recent proposed compression algorithms, Residual Gradient Compression (RGC) is one of the most successful approaches---it can significantly compress the message size (0.1% of the original size) and still preserve accuracy. However, the literature on compressing deep networks focuses almost exclusively on finding good compression rate, while the efficiency of RGC in real implementation has been less investigated. In this paper, we explore the potential of application RGC method in the real distributed system. Targeting the widely adopted multi-GPU system, we proposed an RGC system design call RedSync, which includes a set of optimizations to reduce communication bandwidth while introducing limited overhead. We examine the performance of RedSync on two different multiple GPU platforms, including a supercomputer and a multi-card server. Our test cases include image classification and language modeling tasks on Cifar10, ImageNet, Penn Treebank and Wiki2 datasets. For DNNs featured with high communication to computation ratio, which have long been considered with poor scalability, RedSync shows significant performance improvement.