 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRediscovering Deep Neural Networks in Finite-State Distributions
Paper and Code
Sep 26, 2018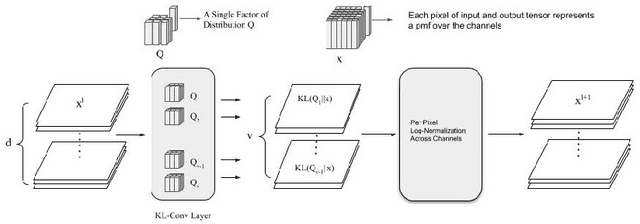
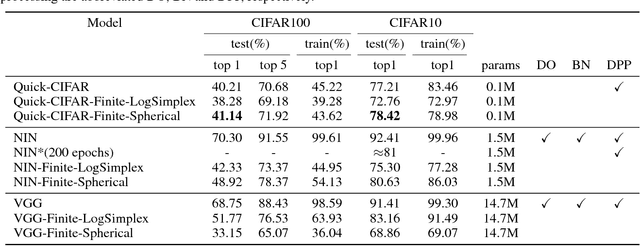
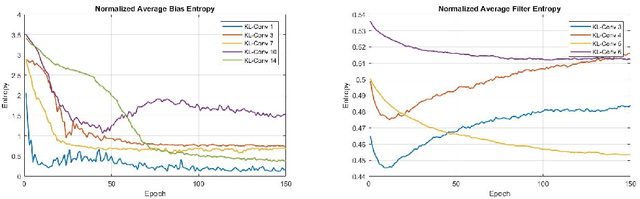
We propose a new way of thinking about deep neural networks, in which the linear and non-linear components of the network are naturally derived and justified in terms of principles in probability theory. In particular, the models constructed in our framework assign probabilities to uncertain realizations, leading to Kullback-Leibler Divergence (KLD) as the linear layer. In our model construction, we also arrive at a structure similar to ReLU activation supported with Bayes' theorem. The non-linearities in our framework are normalization layers with ReLU and Sigmoid as element-wise approximations. Additionally, the pooling function is derived as a marginalization of spatial random variables according to the mechanics of the framework. As such, Max Pooling is an approximation to the aforementioned marginalization process. Since our models are comprised of finite state distributions (FSD) as variables and parameters, exact computation of information-theoretic quantities such as entropy and KLD is possible, thereby providing more objective measures to analyze networks. Unlike existing designs that rely on heuristics, the proposed framework restricts subjective interpretations of CNNs and sheds light on the functionality of neural networks from a completely new perspective.