 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Paper and Code
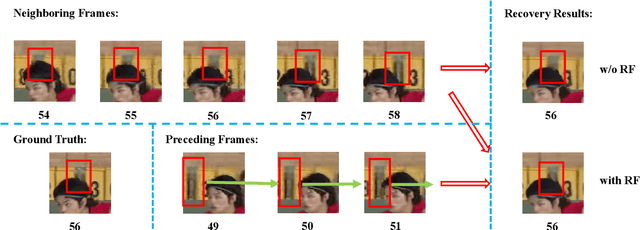
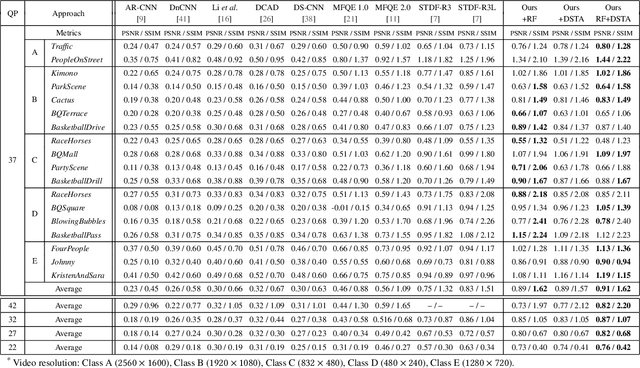
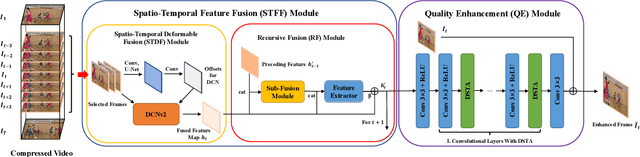
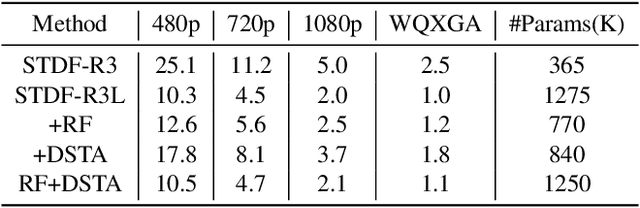
A number of deep learning based algorithms have been proposed to recover high-quality videos from low-quality compressed ones. Among them, some restore the missing details of each frame via exploring the spatiotemporal information of neighboring frames. However, these methods usually suffer from a narrow temporal scope, thus may miss some useful details from some frames outside the neighboring ones. In this paper, to boost artifact removal, on the one hand, we propose a Recursive Fusion (RF) module to model the temporal dependency within a long temporal range. Specifically, RF utilizes both the current reference frames and the preceding hidden state to conduct better spatiotemporal compensation. On the other hand, we design an efficient and effective Deformable Spatiotemporal Attention (DSTA) module such that the model can pay more effort on restoring the artifact-rich areas like the boundary area of a moving object. Extensive experiments show that our method outperforms the existing ones on the MFQE 2.0 dataset in terms of both fidelity and perceptual effect. Code is available at https://github.com/zhaominyiz/RFDA-PyTorch.