 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovery Guarantees of Unsupervised Neural Networks for Inverse Problems trained with Gradient Descent
Paper and Code
Mar 08, 2024


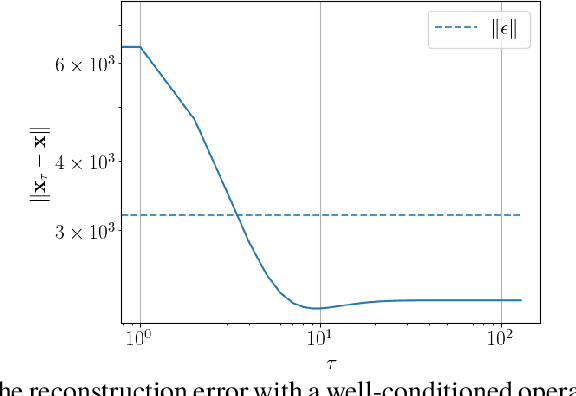
Advanced machine learning methods, and more prominently neural networks, have become standard to solve inverse problems over the last years. However, the theoretical recovery guarantees of such methods are still scarce and difficult to achieve. Only recently did unsupervised methods such as Deep Image Prior (DIP) get equipped with convergence and recovery guarantees for generic loss functions when trained through gradient flow with an appropriate initialization. In this paper, we extend these results by proving that these guarantees hold true when using gradient descent with an appropriately chosen step-size/learning rate. We also show that the discretization only affects the overparametrization bound for a two-layer DIP network by a constant and thus that the different guarantees found for the gradient flow will hold for gradient descent.