 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of Visually Perceived Compositional Human Actions by Multiple Spatio-Temporal Scales Recurrent Neural Networks
Paper and Code
Feb 22, 2017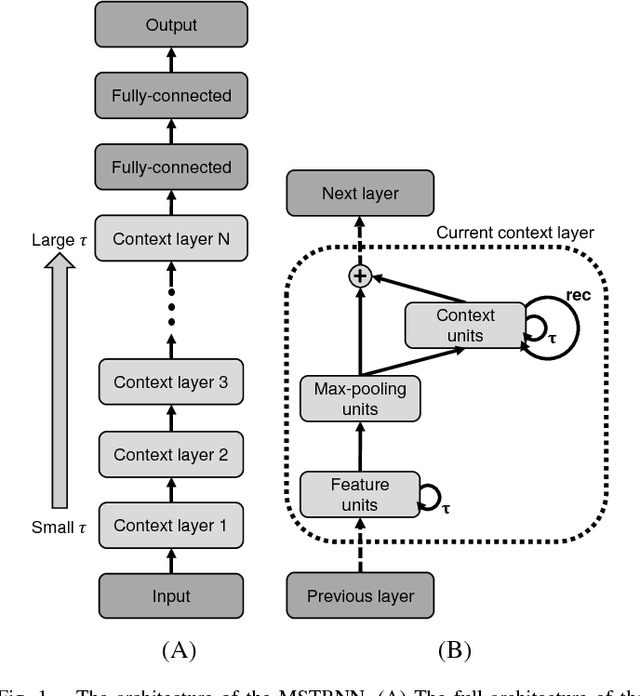
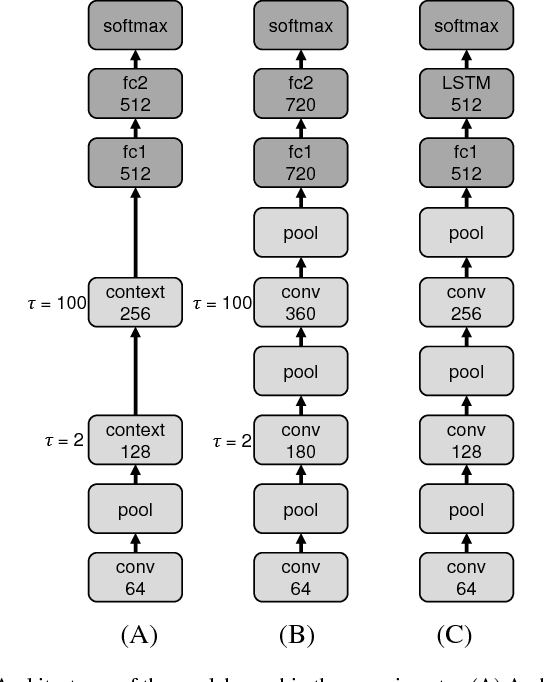

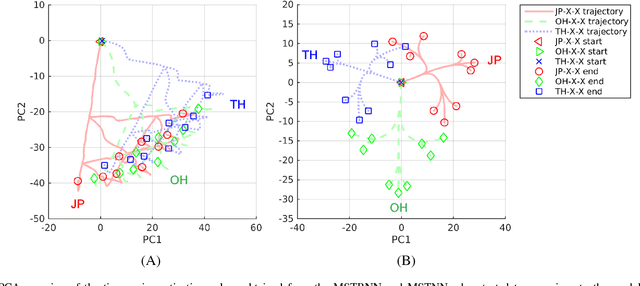
The current paper proposes a novel neural network model for recognizing visually perceived human actions. The proposed multiple spatio-temporal scales recurrent neural network (MSTRNN) model is derived by introducing multiple timescale recurrent dynamics to the conventional convolutional neural network model. One of the essential characteristics of the MSTRNN is that its architecture imposes both spatial and temporal constraints simultaneously on the neural activity which vary in multiple scales among different layers. As suggested by the principle of the upward and downward causation, it is assumed that the network can develop meaningful structures such as functional hierarchy by taking advantage of such constraints during the course of learning. To evaluate the characteristics of the model, the current study uses three types of human action video dataset consisting of different types of primitive actions and different levels of compositionality on them. The performance of the MSTRNN in testing with these dataset is compared with the ones by other representative deep learning models used in the field. The analysis of the internal representation obtained through the learning with the dataset clarifies what sorts of functional hierarchy can be developed by extracting the essential compositionality underlying the dataset.