 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealtime Global Attention Network for Semantic Segmentation
Paper and Code
Dec 24, 2021
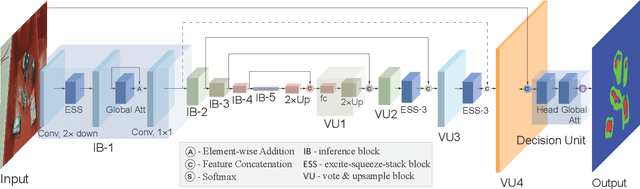

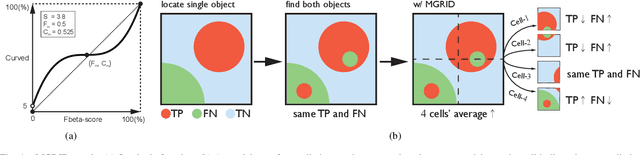
In this paper, we proposed an end-to-end realtime global attention neural network (RGANet) for the challenging task of semantic segmentation. Different from the encoding strategy deployed by self-attention paradigms, the proposed global attention module encodes global attention via depth-wise convolution and affine transformations. The integration of these global attention modules into a hierarchy architecture maintains high inferential performance. In addition, an improved evaluation metric, namely MGRID, is proposed to alleviate the negative effect of non-convex, widely scattered ground-truth areas. Results from extensive experiments on state-of-the-art architectures for semantic segmentation manifest the leading performance of proposed approaches for robotic monocular visual perception.