 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-parameterizing VAEs for stability
Paper and Code
Jun 25, 2021
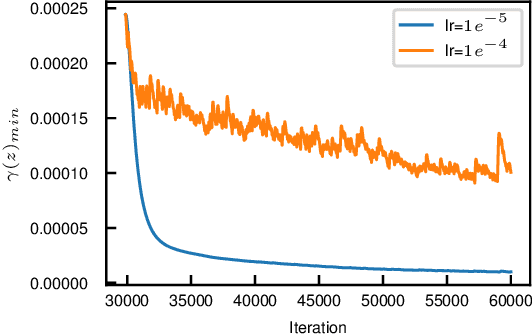
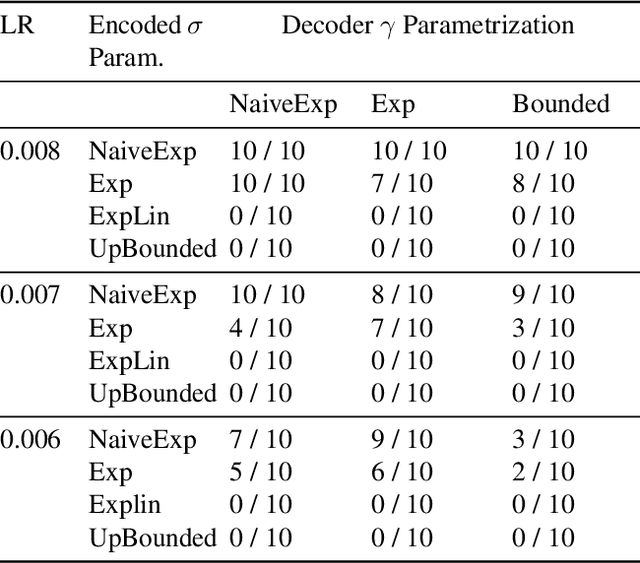
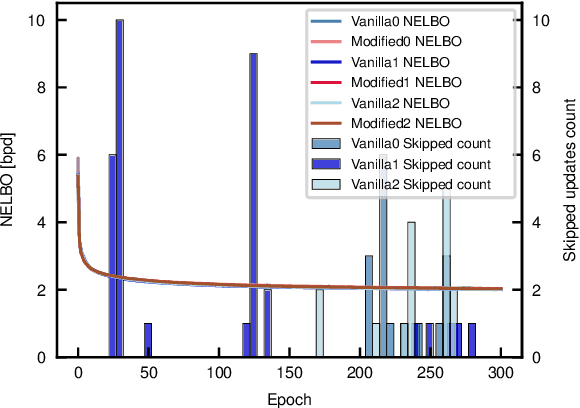
We propose a theoretical approach towards the training numerical stability of Variational AutoEncoders (VAE). Our work is motivated by recent studies empowering VAEs to reach state of the art generative results on complex image datasets. These very deep VAE architectures, as well as VAEs using more complex output distributions, highlight a tendency to haphazardly produce high training gradients as well as NaN losses. The empirical fixes proposed to train them despite their limitations are neither fully theoretically grounded nor generally sufficient in practice. Building on this, we localize the source of the problem at the interface between the model's neural networks and their output probabilistic distributions. We explain a common source of instability stemming from an incautious formulation of the encoded Normal distribution's variance, and apply the same approach on other, less obvious sources. We show that by implementing small changes to the way we parameterize the Normal distributions on which they rely, VAEs can securely be trained.