 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-examination of the Role of Latent Variables in Sequence Modeling
Paper and Code
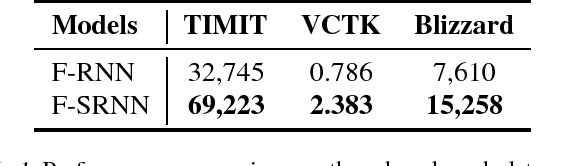

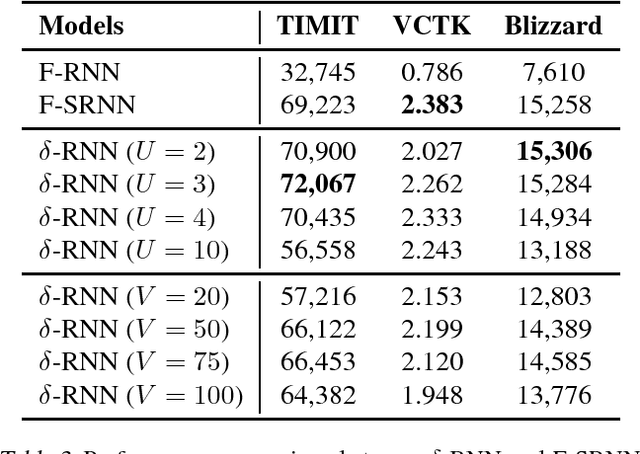
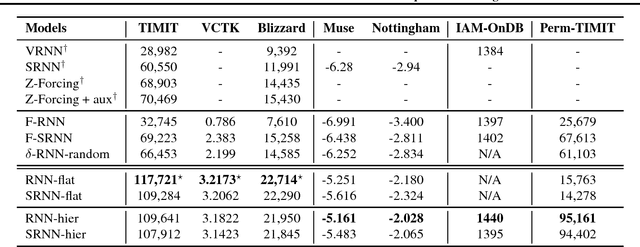
With latent variables, stochastic recurrent models have achieved state-of-the-art performance in modeling sound-wave sequence. However, opposite results are also observed in other domains, where standard recurrent networks often outperform stochastic models. To better understand this discrepancy, we re-examine the roles of latent variables in stochastic recurrent models for speech density estimation. Our analysis reveals that under the restriction of fully factorized output distribution in previous evaluations, the stochastic models were implicitly leveraging intra-step correlation but the standard recurrent baselines were prohibited to do so, resulting in an unfair comparison. To correct the unfairness, we remove such restriction in our re-examination, where all the models can explicitly leverage intra-step correlation with an auto-regressive structure. Over a diverse set of sequential data, including human speech, MIDI music, handwriting trajectory and frame-permuted speech, our results show that stochastic recurrent models fail to exhibit any practical advantage despite the claimed theoretical superiority. In contrast, standard recurrent models equipped with an auto-regressive output distribution consistently perform better, significantly advancing the state-of-the-art results on three speech datasets.