 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare event failure test case generation in Learning-Enabled-Controllers
Paper and Code
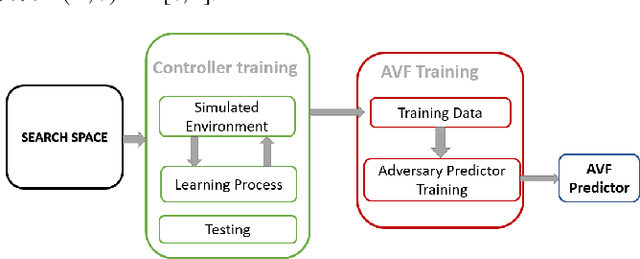
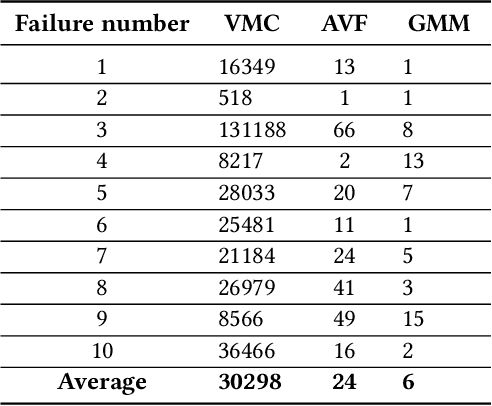


Machine learning models have prevalent applications in many real-world problems, which increases the importance of correctness in the behaviour of these trained models. Finding a good test case that can reveal the potential failure in these trained systems can help to retrain these models to increase their correctness. For a well-trained model, the occurrence of a failure is rare. Consequently, searching these rare scenarios by evaluating each sample in input search space or randomized search would be costly and sometimes intractable due to large search space, limited computational resources, and available time. In this paper, we tried to address this challenge of finding these failure scenarios faster than traditional randomized search. The central idea of our approach is to separate the input data space in region of high failure probability and region of low/minimal failure probability based on the observation made by training data, data drawn from real-world statistics, and knowledge from a domain expert. Using these information, we can design a generative model from which we can generate scenarios that have a high likelihood to reveal the potential failure. We evaluated this approach on two different experimental scenarios and able to speed up the discovery of such failures a thousand-fold faster than the traditional randomized search.