 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPID: Training-free Retrieval-based Log Anomaly Detection with PLM considering Token-level information
Paper and Code
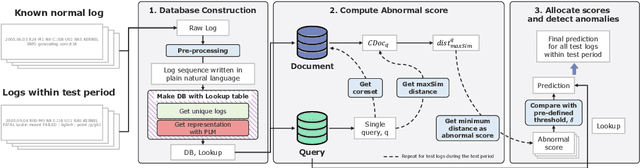
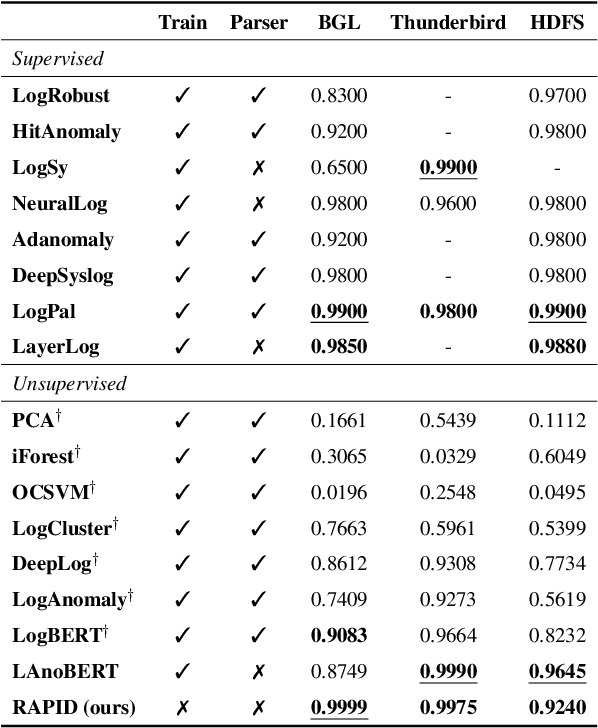

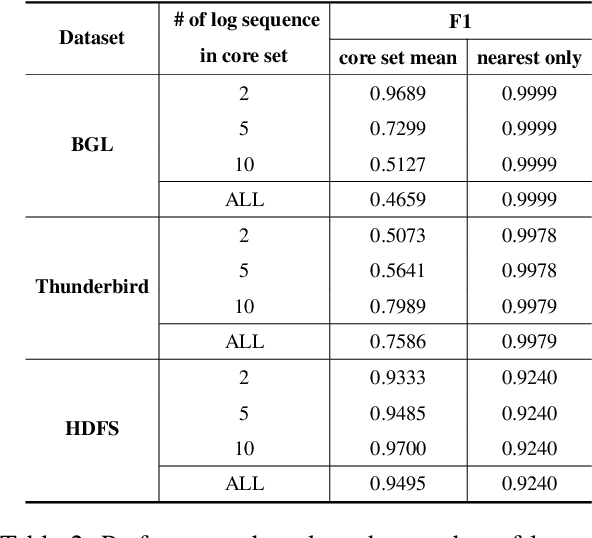
As the IT industry advances, system log data becomes increasingly crucial. Many computer systems rely on log texts for management due to restricted access to source code. The need for log anomaly detection is growing, especially in real-world applications, but identifying anomalies in rapidly accumulating logs remains a challenging task. Traditional deep learning-based anomaly detection models require dataset-specific training, leading to corresponding delays. Notably, most methods only focus on sequence-level log information, which makes the detection of subtle anomalies harder, and often involve inference processes that are difficult to utilize in real-time. We introduce RAPID, a model that capitalizes on the inherent features of log data to enable anomaly detection without training delays, ensuring real-time capability. RAPID treats logs as natural language, extracting representations using pre-trained language models. Given that logs can be categorized based on system context, we implement a retrieval-based technique to contrast test logs with the most similar normal logs. This strategy not only obviates the need for log-specific training but also adeptly incorporates token-level information, ensuring refined and robust detection, particularly for unseen logs. We also propose the core set technique, which can reduce the computational cost needed for comparison. Experimental results show that even without training on log data, RAPID demonstrates competitive performance compared to prior models and achieves the best performance on certain datasets. Through various research questions, we verified its capability for real-time detection without delay.