 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Risk Minimization with Bayesian Models Through Deep Learning Approximation
Paper and Code
Mar 29, 2021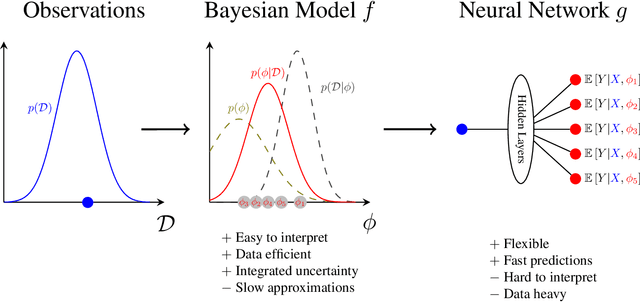
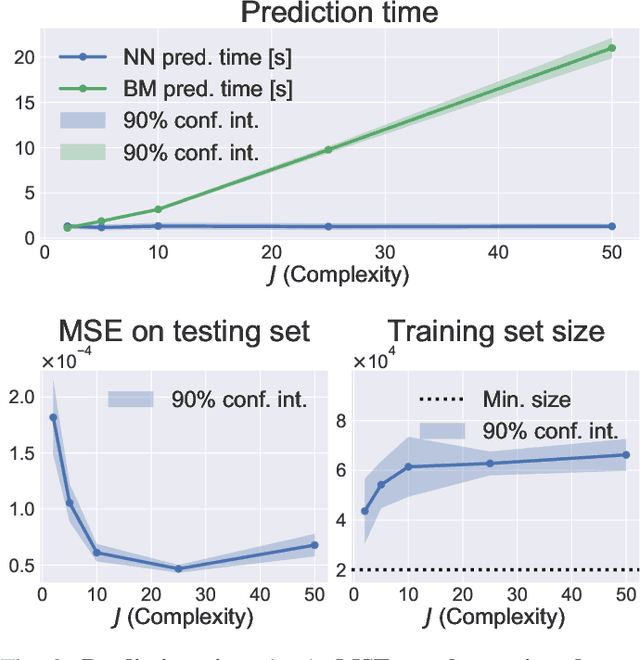
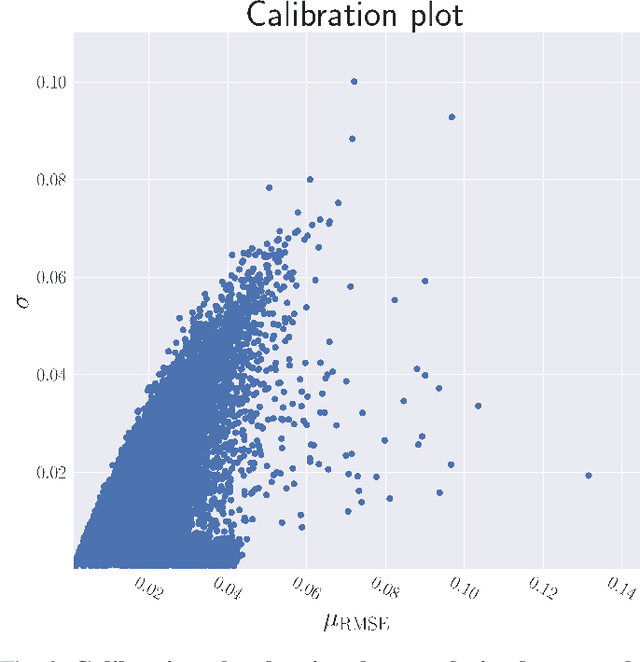
In this paper, we introduce a novel combination of Bayesian Models (BMs) and Neural Networks (NNs) for making predictions with a minimum expected risk. Our approach combines the best of both worlds, the data efficiency and interpretability of a BM with the speed of a NN. For a BM, making predictions with the lowest expected loss requires integrating over the posterior distribution. In cases for which exact inference of the posterior predictive distribution is intractable, approximation methods are typically applied, e.g. Monte Carlo (MC) simulation. The more samples, the higher the accuracy -- but at the expense of increased computational cost. Our approach removes the need for iterative MC simulation on the CPU at prediction time. In brief, it works by fitting a NN to synthetic data generated using the BM. In a single feed-forward pass of the NN, it gives a set of point-wise approximations to the BM's posterior predictive distribution for a given observation. We achieve risk minimized predictions significantly faster than standard methods with a negligible loss on the testing dataset. We combine this approach with Active Learning (AL) to minimize the amount of data required for fitting the NN. This is done by iteratively labeling more data in regions with high predictive uncertainty of the NN.