 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking by Dependence - A Fair Criteria
Paper and Code
Jun 27, 2012
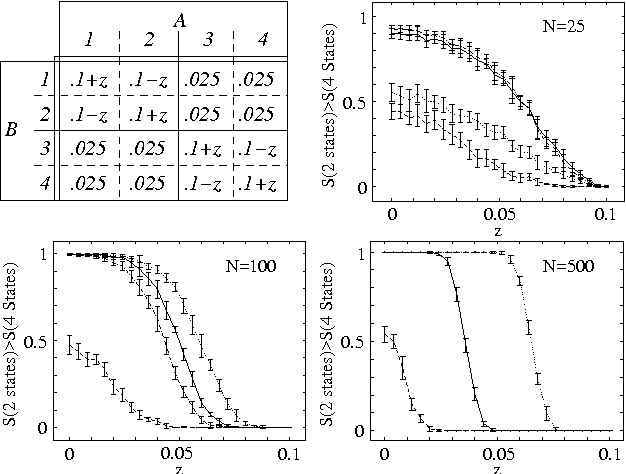
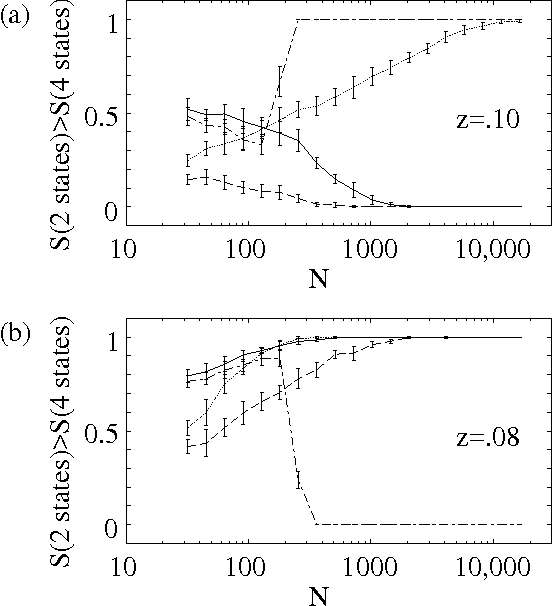

Estimating the dependences between random variables, and ranking them accordingly, is a prevalent problem in machine learning. Pursuing frequentist and information-theoretic approaches, we first show that the p-value and the mutual information can fail even in simplistic situations. We then propose two conditions for regularizing an estimator of dependence, which leads to a simple yet effective new measure. We discuss its advantages and compare it to well-established model-selection criteria. Apart from that, we derive a simple constraint for regularizing parameter estimates in a graphical model. This results in an analytical approximation for the optimal value of the equivalent sample size, which agrees very well with the more involved Bayesian approach in our experiments.