 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking-aware Uncertainty for Text-guided Image Retrieval
Paper and Code
Aug 16, 2023


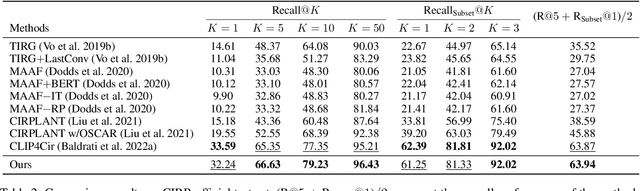
Text-guided image retrieval is to incorporate conditional text to better capture users' intent. Traditionally, the existing methods focus on minimizing the embedding distances between the source inputs and the targeted image, using the provided triplets $\langle$source image, source text, target image$\rangle$. However, such triplet optimization may limit the learned retrieval model to capture more detailed ranking information, e.g., the triplets are one-to-one correspondences and they fail to account for many-to-many correspondences arising from semantic diversity in feedback languages and images. To capture more ranking information, we propose a novel ranking-aware uncertainty approach to model many-to-many correspondences by only using the provided triplets. We introduce uncertainty learning to learn the stochastic ranking list of features. Specifically, our approach mainly comprises three components: (1) In-sample uncertainty, which aims to capture semantic diversity using a Gaussian distribution derived from both combined and target features; (2) Cross-sample uncertainty, which further mines the ranking information from other samples' distributions; and (3) Distribution regularization, which aligns the distributional representations of source inputs and targeted image. Compared to the existing state-of-the-art methods, our proposed method achieves significant results on two public datasets for composed image retrieval.