 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom walk kernels and learning curves for Gaussian process regression on random graphs
Paper and Code
Sep 30, 2013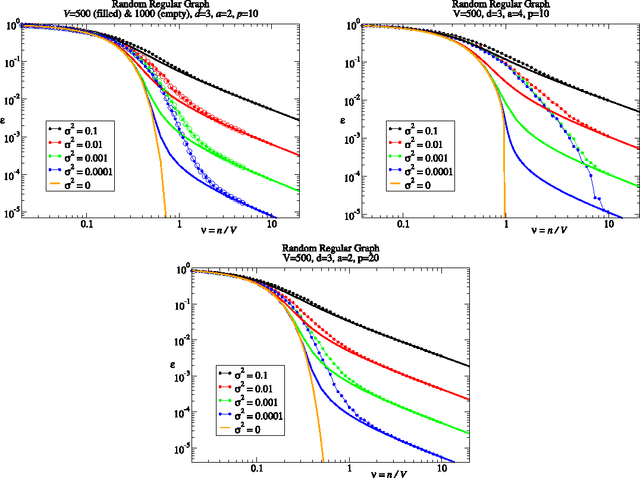
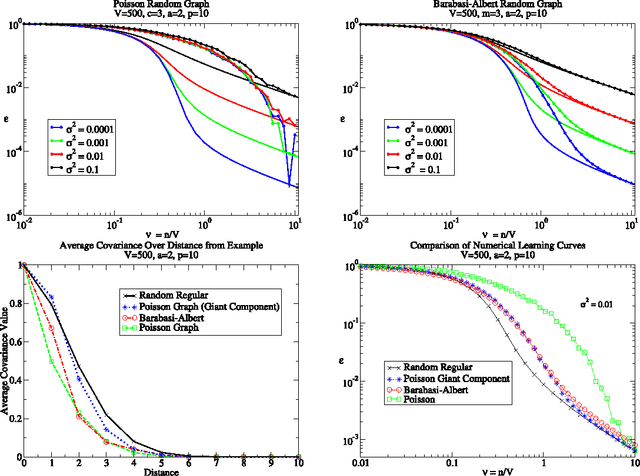
We consider learning on graphs, guided by kernels that encode similarity between vertices. Our focus is on random walk kernels, the analogues of squared exponential kernels in Euclidean spaces. We show that on large, locally treelike, graphs these have some counter-intuitive properties, specifically in the limit of large kernel lengthscales. We consider using these kernels as covariance matrices of e.g.\ Gaussian processes (GPs). In this situation one typically scales the prior globally to normalise the average of the prior variance across vertices. We demonstrate that, in contrast to the Euclidean case, this generically leads to significant variation in the prior variance across vertices, which is undesirable from the probabilistic modelling point of view. We suggest the random walk kernel should be normalised locally, so that each vertex has the same prior variance, and analyse the consequences of this by studying learning curves for Gaussian process regression. Numerical calculations as well as novel theoretical predictions for the learning curves using belief propagation make it clear that one obtains distinctly different probabilistic models depending on the choice of normalisation. Our method for predicting the learning curves using belief propagation is significantly more accurate than previous approximations and should become exact in the limit of large random graphs.