 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-LoRA: Random Initialization of Multi-Head LoRA for Multi-Task Learning
Paper and Code
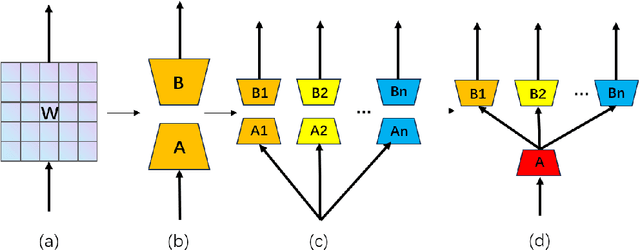
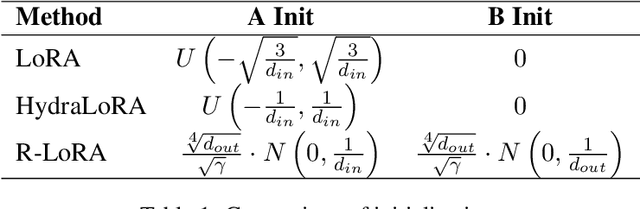
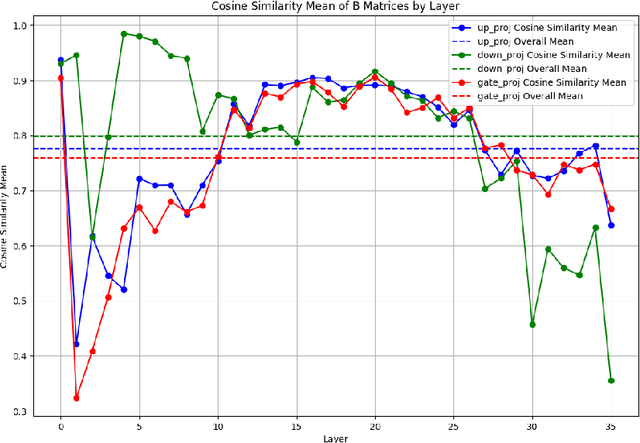
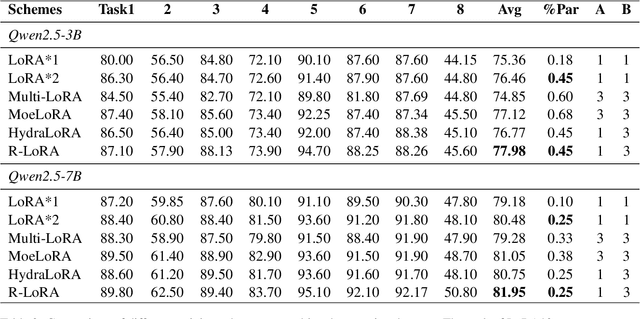
Fine-tuning large language models (LLMs) is prohibitively expensive in terms of computational and memory costs. Low-rank Adaptation (LoRA), as one of the most popular parameter-efficient fine-tuning (PEFT) methods, offers a cost-effective alternative by approximating the model changes $\Delta W \in \mathbb{R}^{m \times n}$ through the product of down-projection matrix $A \in \mathbb{R}^{m \times r}$ and head matrix $B \in \mathbb{R}^{r \times n}$, where $r \ll \min(m, n)$. In real-world scenarios, LLMs are fine-tuned on data from multiple domains to perform tasks across various fields, embodying multi-task learning (MTL). LoRA often underperforms in such complex scenarios. To enhance LoRA's capability in multi-task learning, we propose R-LoRA, which incorporates Multi-Head Randomization. Multi-Head Randomization diversifies the head matrices through Multi-Head Random Initialization and Multi-Head Dropout, enabling more efficient learning of task-specific features while maintaining shared knowledge representation. Extensive experiments demonstrate that R-LoRA is better at capturing task-specific knowledge, thereby improving performance in multi-task scenarios. The code is available at https://github.com/jinda-liu/R-LoRA.