 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edger-G2P: Evaluating and Enhancing Robustness of Grapheme to Phoneme Conversion by Controlled noise introducing and Contextual information incorporation
Paper and Code
Feb 21, 2022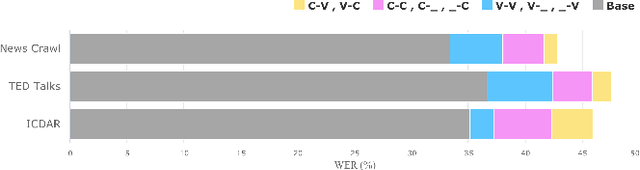
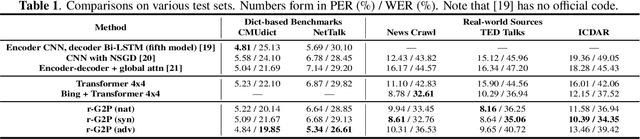
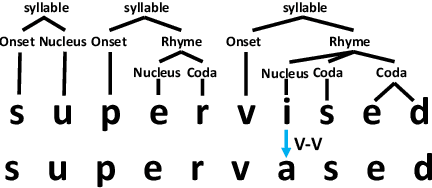
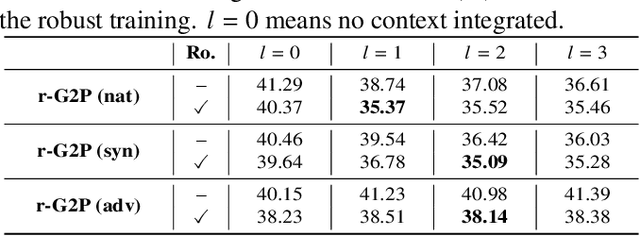
Grapheme-to-phoneme (G2P) conversion is the process of converting the written form of words to their pronunciations. It has an important role for text-to-speech (TTS) synthesis and automatic speech recognition (ASR) systems. In this paper, we aim to evaluate and enhance the robustness of G2P models. We show that neural G2P models are extremely sensitive to orthographical variations in graphemes like spelling mistakes. To solve this problem, we propose three controlled noise introducing methods to synthesize noisy training data. Moreover, we incorporate the contextual information with the baseline and propose a robust training strategy to stabilize the training process. The experimental results demonstrate that our proposed robust G2P model (r-G2P) outperforms the baseline significantly (-2.73\% WER on Dict-based benchmarks and -9.09\% WER on Real-world sources).