Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Conditioned Counterfactual Image Generation for VQA
Paper and Code
Nov 14, 2019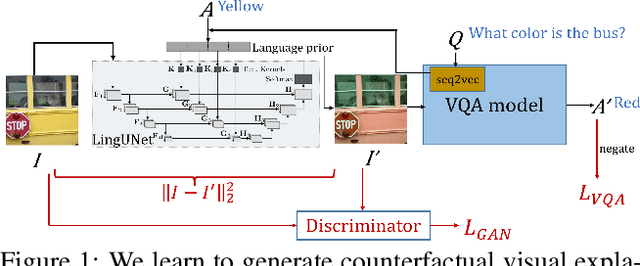

While Visual Question Answering (VQA) models continue to push the state-of-the-art forward, they largely remain black-boxes - failing to provide insight into how or why an answer is generated. In this ongoing work, we propose addressing this shortcoming by learning to generate counterfactual images for a VQA model - i.e. given a question-image pair, we wish to generate a new image such that i) the VQA model outputs a different answer, ii) the new image is minimally different from the original, and iii) the new image is realistic. Our hope is that providing such counterfactual examples allows users to investigate and understand the VQA model's internal mechanisms.
* Accepted by the VQA Workshop at CVPR 2019
View paper on