 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-LIFE: Query-aware Language Image Fusion Embedding for E-Commerce Relevance
Paper and Code
Nov 26, 2023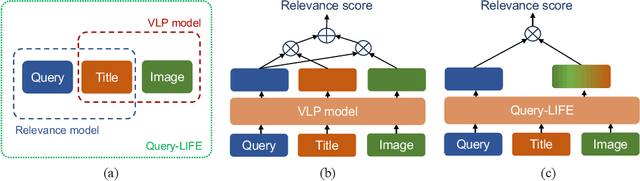

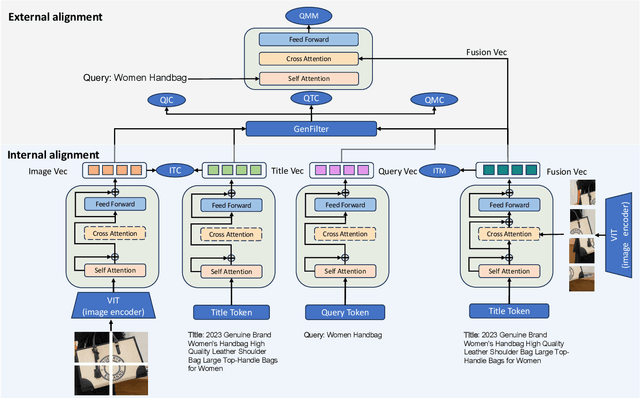

Relevance module plays a fundamental role in e-commerce search as they are responsible for selecting relevant products from thousands of items based on user queries, thereby enhancing users experience and efficiency. The traditional approach models the relevance based product titles and queries, but the information in titles alone maybe insufficient to describe the products completely. A more general optimization approach is to further leverage product image information. In recent years, vision-language pre-training models have achieved impressive results in many scenarios, which leverage contrastive learning to map both textual and visual features into a joint embedding space. In e-commerce, a common practice is to fine-tune on the pre-trained model based on e-commerce data. However, the performance is sub-optimal because the vision-language pre-training models lack of alignment specifically designed for queries. In this paper, we propose a method called Query-LIFE (Query-aware Language Image Fusion Embedding) to address these challenges. Query-LIFE utilizes a query-based multimodal fusion to effectively incorporate the image and title based on the product types. Additionally, it employs query-aware modal alignment to enhance the accuracy of the comprehensive representation of products. Furthermore, we design GenFilt, which utilizes the generation capability of large models to filter out false negative samples and further improve the overall performance of the contrastive learning task in the model. Experiments have demonstrated that Query-LIFE outperforms existing baselines. We have conducted ablation studies and human evaluations to validate the effectiveness of each module within Query-LIFE. Moreover, Query-LIFE has been deployed on Miravia Search, resulting in improved both relevance and conversion efficiency.