 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Adaptive Predictive Inference with Partial Labels
Paper and Code
Jun 15, 2022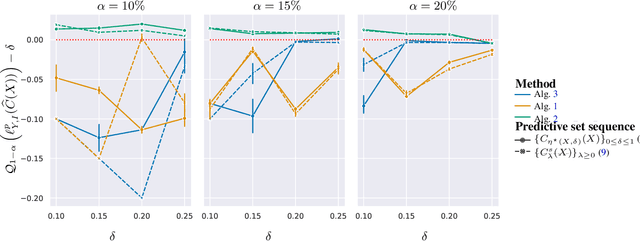
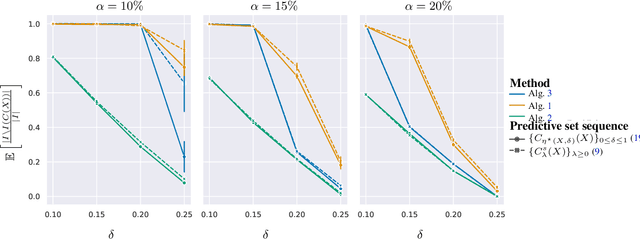
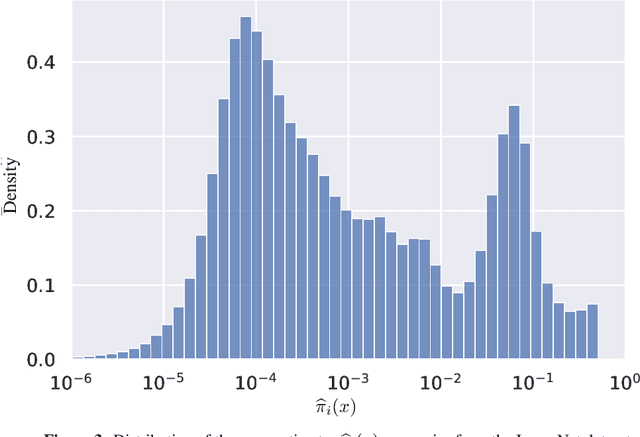
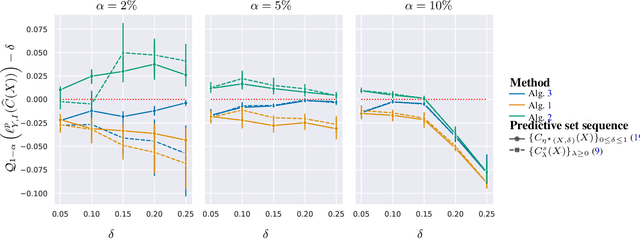
The cost and scarcity of fully supervised labels in statistical machine learning encourage using partially labeled data for model validation as a cheaper and more accessible alternative. Effectively collecting and leveraging weakly supervised data for large-space structured prediction tasks thus becomes an important part of an end-to-end learning system. We propose a new computationally-friendly methodology to construct predictive sets using only partially labeled data on top of black-box predictive models. To do so, we introduce "probe" functions as a way to describe weakly supervised instances and define a false discovery proportion-type loss, both of which seamlessly adapt to partial supervision and structured prediction -- ranking, matching, segmentation, multilabel or multiclass classification. Our experiments highlight the validity of our predictive set construction as well as the attractiveness of a more flexible user-dependent loss framework.