 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum machine learning with glow for episodic tasks and decision games
Paper and Code
Jan 27, 2016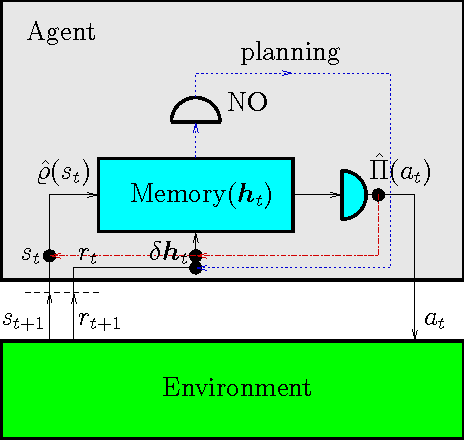
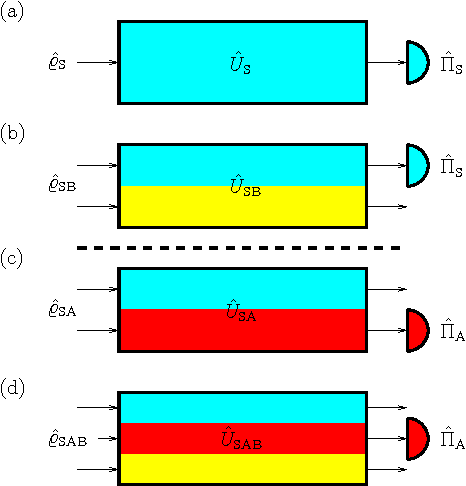
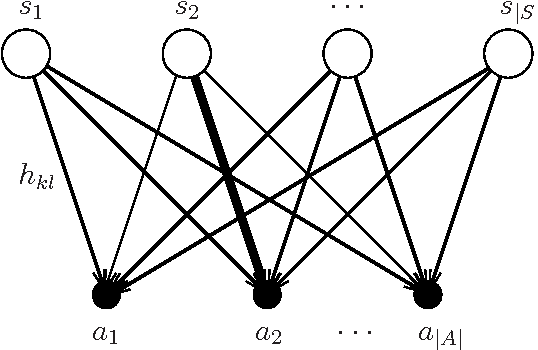
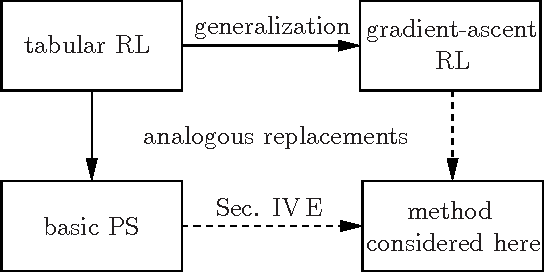
We consider a general class of models, where a reinforcement learning (RL) agent learns from cyclic interactions with an external environment via classical signals. Perceptual inputs are encoded as quantum states, which are subsequently transformed by a quantum channel representing the agent's memory, while the outcomes of measurements performed at the channel's output determine the agent's actions. The learning takes place via stepwise modifications of the channel properties. They are described by an update rule that is inspired by the projective simulation (PS) model and equipped with a glow mechanism that allows for a backpropagation of policy changes, analogous to the eligibility traces in RL and edge glow in PS. In this way, the model combines features of PS with the ability for generalization, offered by its physical embodiment as a quantum system. We apply the agent to various setups of an invasion game and a grid world, which serve as elementary model tasks allowing a direct comparison with a basic classical PS agent.