 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum linear algebra is all you need for Transformer architectures
Paper and Code
Feb 26, 2024
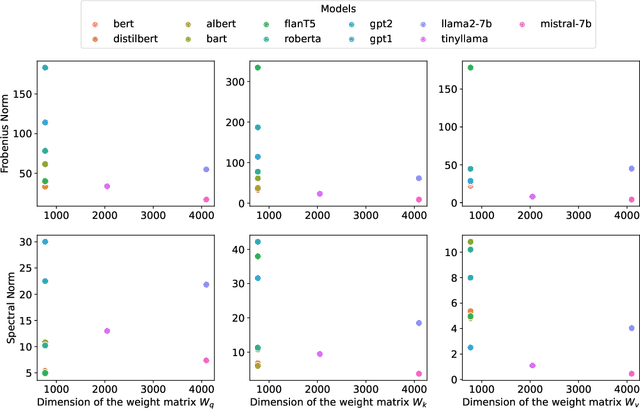

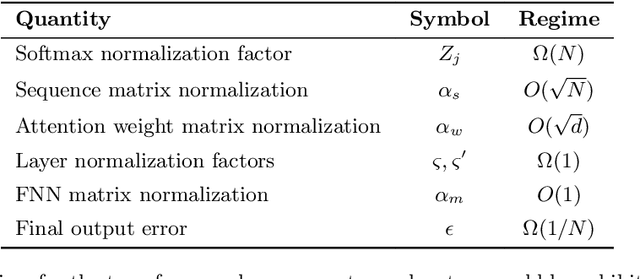
Generative machine learning methods such as large-language models are revolutionizing the creation of text and images. While these models are powerful they also harness a large amount of computational resources. The transformer is a key component in large language models that aims to generate a suitable completion of a given partial sequence. In this work, we investigate transformer architectures under the lens of fault-tolerant quantum computing. The input model is one where pre-trained weight matrices are given as block encodings to construct the query, key, and value matrices for the transformer. As a first step, we show how to prepare a block encoding of the self-attention matrix, with a row-wise application of the softmax function using the Hadamard product. In addition, we combine quantum subroutines to construct important building blocks in the transformer, the residual connection, layer normalization, and the feed-forward neural network. Our subroutines prepare an amplitude encoding of the transformer output, which can be measured to obtain a prediction. We discuss the potential and challenges for obtaining a quantum advantage.