Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Criticism: A Tagged News Corpus Analysed for Sentiment and Named Entities
Paper and Code
Jun 05, 2020
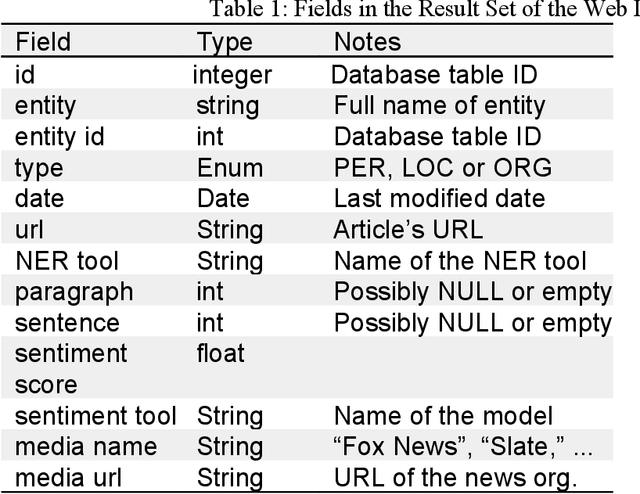
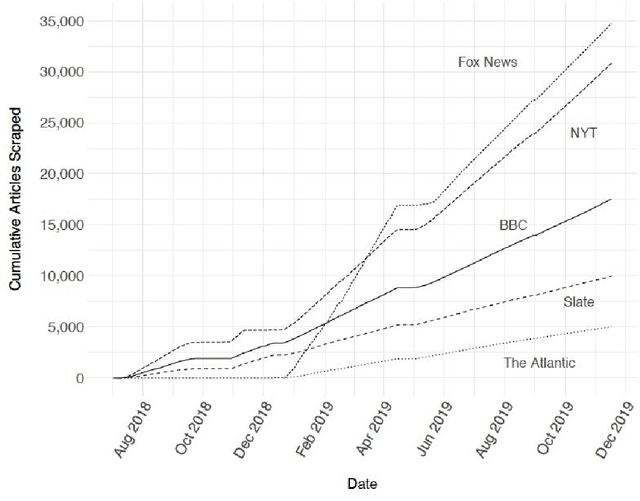

In this research, we continuously collect data from the RSS feeds of traditional news sources. We apply several pre-trained implementations of named entity recognition (NER) tools, quantifying the success of each implementation. We also perform sentiment analysis of each news article at the document, paragraph and sentence level, with the goal of creating a corpus of tagged news articles that is made available to the public through a web interface. Finally, we show how the data in this corpus could be used to identify bias in news reporting.
View paper on