 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Stopword Generation for Sentiment Analysis via Recursive and Iterative Deletion
Paper and Code
Sep 04, 2022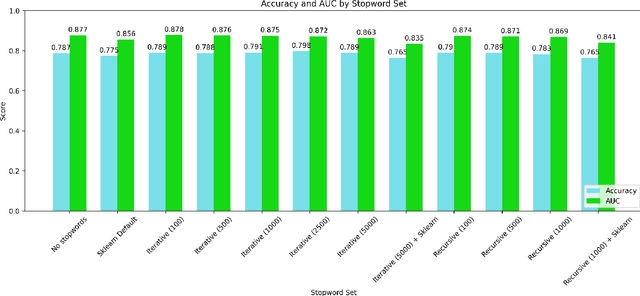
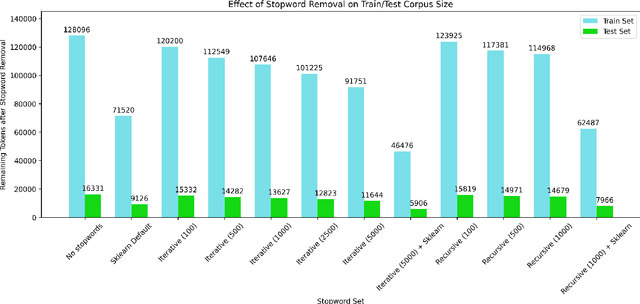
Stopwords carry little semantic information and are often removed from text data to reduce dataset size and improve machine learning model performance. Consequently, researchers have sought to develop techniques for generating effective stopword sets. Previous approaches have ranged from qualitative techniques relying upon linguistic experts, to statistical approaches that extract word importance using correlations or frequency-dependent metrics computed on a corpus. We present a novel quantitative approach that employs iterative and recursive feature deletion algorithms to see which words can be deleted from a pre-trained transformer's vocabulary with the least degradation to its performance, specifically for the task of sentiment analysis. Empirically, stopword lists generated via this approach drastically reduce dataset size while negligibly impacting model performance, in one such example shrinking the corpus by 28.4% while improving the accuracy of a trained logistic regression model by 0.25%. In another instance, the corpus was shrunk by 63.7% with a 2.8% decrease in accuracy. These promising results indicate that our approach can generate highly effective stopword sets for specific NLP tasks.