 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Effects of Enforcing Disentanglement on Variational Autoencoders
Paper and Code
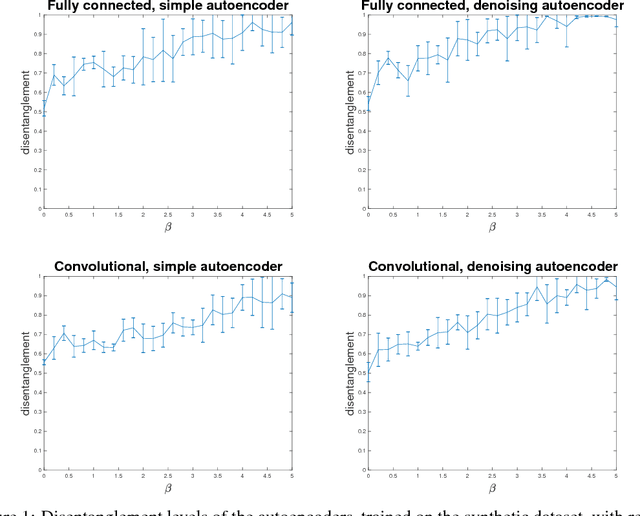
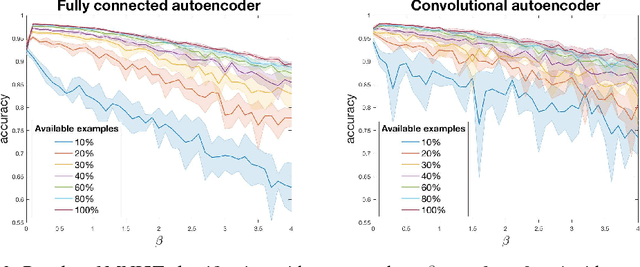
The notion of disentangled autoencoders was proposed as an extension to the variational autoencoder by introducing a disentanglement parameter $\beta$, controlling the learning pressure put on the possible underlying latent representations. For certain values of $\beta$ this kind of autoencoders is capable of encoding independent input generative factors in separate elements of the code, leading to a more interpretable and predictable model behaviour. In this paper we quantify the effects of the parameter $\beta$ on the model performance and disentanglement. After training multiple models with the same value of $\beta$, we establish the existence of consistent variance in one of the disentanglement measures, proposed in literature. The negative consequences of the disentanglement to the autoencoder's discriminative ability are also asserted while varying the amount of examples available during training.