 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Conceptual Error in Dimensionality Reduction
Paper and Code
Jun 12, 2021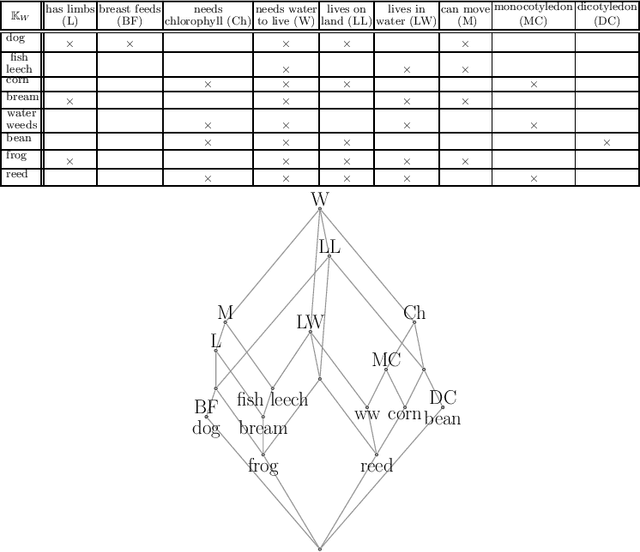
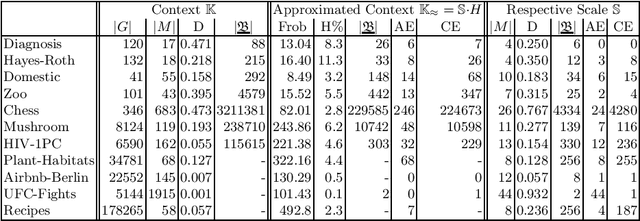
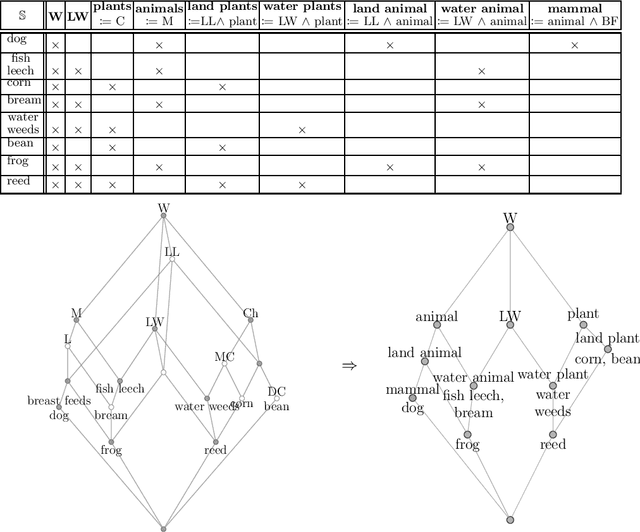
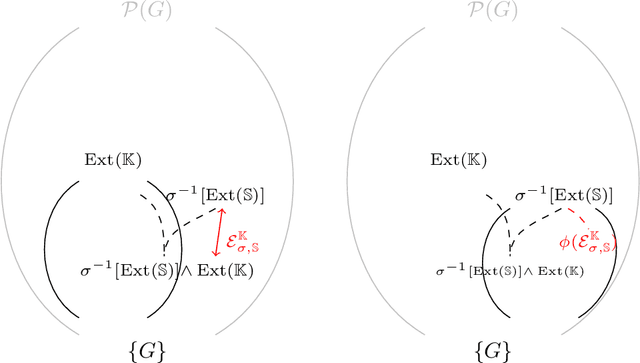
Dimension reduction of data sets is a standard problem in the realm of machine learning and knowledge reasoning. They affect patterns in and dependencies on data dimensions and ultimately influence any decision-making processes. Therefore, a wide variety of reduction procedures are in use, each pursuing different objectives. A so far not considered criterion is the conceptual continuity of the reduction mapping, i.e., the preservation of the conceptual structure with respect to the original data set. Based on the notion scale-measure from formal concept analysis we present in this work a) the theoretical foundations to detect and quantify conceptual errors in data scalings; b) an experimental investigation of our approach on eleven data sets that were respectively treated with a variant of non-negative matrix factorization.