 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Metrics in Recommender Systems: Do We Calculate Metrics Consistently?
Paper and Code
Jun 26, 2022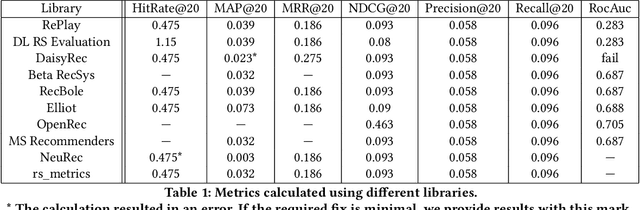
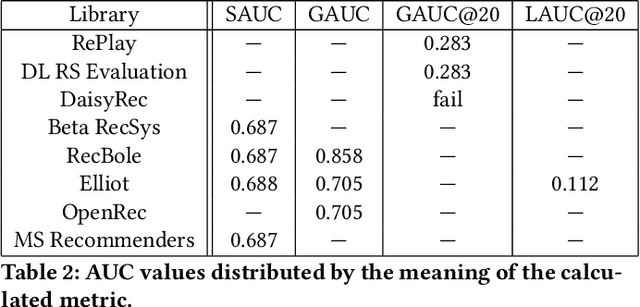

Offline evaluation is a popular approach to determine the best algorithm in terms of the chosen quality metric. However, if the chosen metric calculates something unexpected, this miscommunication can lead to poor decisions and wrong conclusions. In this paper, we thoroughly investigate quality metrics used for recommender systems evaluation. We look at the practical aspect of implementations found in modern RecSys libraries and at the theoretical aspect of definitions in academic papers. We find that Precision is the only metric universally understood among papers and libraries, while other metrics may have different interpretations. Metrics implemented in different libraries sometimes have the same name but measure different things, which leads to different results given the same input. When defining metrics in an academic paper, authors sometimes omit explicit formulations or give references that do not contain explanations either. In 47% of cases, we cannot easily know how the metric is defined because the definition is not clear or absent. These findings highlight yet another difficulty in recommender system evaluation and call for a more detailed description of evaluation protocols.