 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePT43D: A Probabilistic Transformer for Generating 3D Shapes from Single Highly-Ambiguous RGB Images
Paper and Code
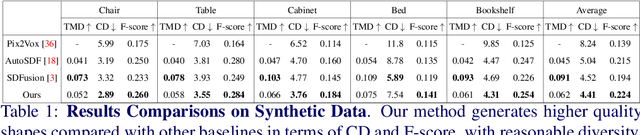
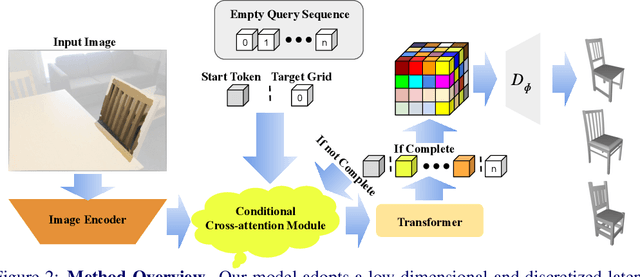

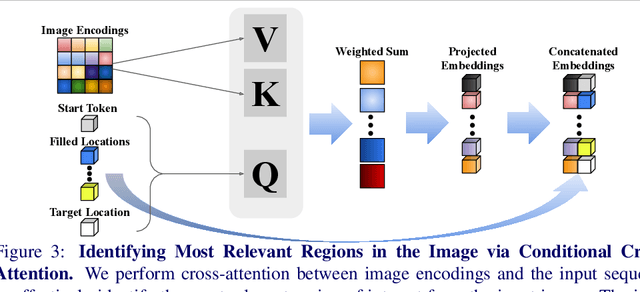
Generating 3D shapes from single RGB images is essential in various applications such as robotics. Current approaches typically target images containing clear and complete visual descriptions of the object, without considering common realistic cases where observations of objects that are largely occluded or truncated. We thus propose a transformer-based autoregressive model to generate the probabilistic distribution of 3D shapes conditioned on an RGB image containing potentially highly ambiguous observations of the object. To handle realistic scenarios such as occlusion or field-of-view truncation, we create simulated image-to-shape training pairs that enable improved fine-tuning for real-world scenarios. We then adopt cross-attention to effectively identify the most relevant region of interest from the input image for shape generation. This enables inference of sampled shapes with reasonable diversity and strong alignment with the input image. We train and test our model on our synthetic data then fine-tune and test it on real-world data. Experiments demonstrate that our model outperforms state of the art in both scenarios