 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Classification using Machine Learning and Statistical Techniques: A Comparative Analysis
Paper and Code
Jan 18, 2019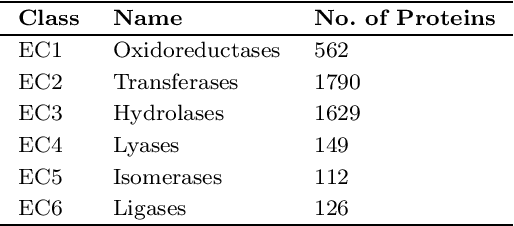
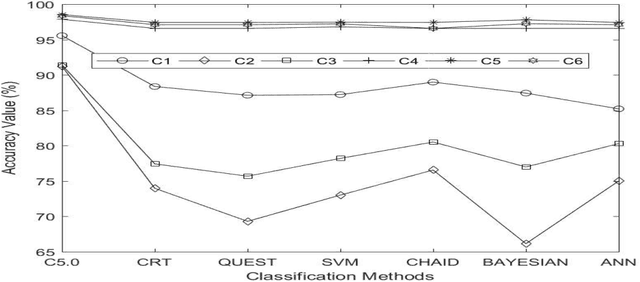

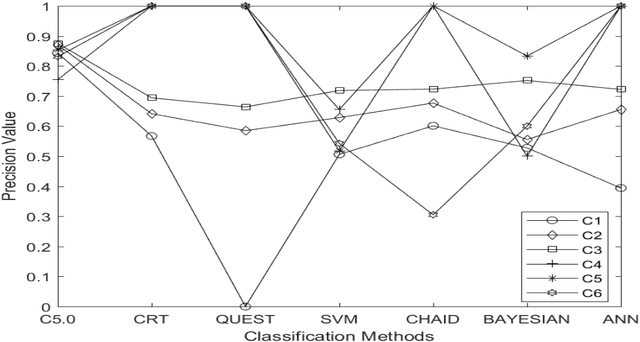
In recent era prediction of enzyme class from an unknown protein is one of the challenging tasks in bioinformatics. Day to day the number of proteins is increases as result the prediction of enzyme class gives a new opportunity to bioinformatics scholars. The prime objective of this article is to implement the machine learning classification technique for feature selection and predictions also find out an appropriate classification technique for function prediction. In this article the seven different classification technique like CRT, QUEST, CHAID, C5.0, ANN (Artificial Neural Network), SVM and Bayesian has been implemented on 4368 protein data that has been extracted from UniprotKB databank and categories into six different class. The proteins data is high dimensional sequence data and contain a maximum of 48 features.To manipulate the high dimensional sequential protein data with different classification technique, the SPSS has been used as an experimental tool. Different classification techniques give different results for every model and shows that the data are imbalanced for class C4, C5 and C6. The imbalanced data affect the performance of model. In these three classes the precision and recall value is very less or negligible. The experimental results highlight that the C5.0 classification technique accuracy is more suited for protein feature classification and predictions. The C5.0 classification technique gives 95.56% accuracy and also gives high precision and recall value. Finally, we conclude that the features that is selected can be used for function prediction.