 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Genomic Privacy by a Sequence-Similarity Based Obfuscation Method
Paper and Code
Aug 08, 2017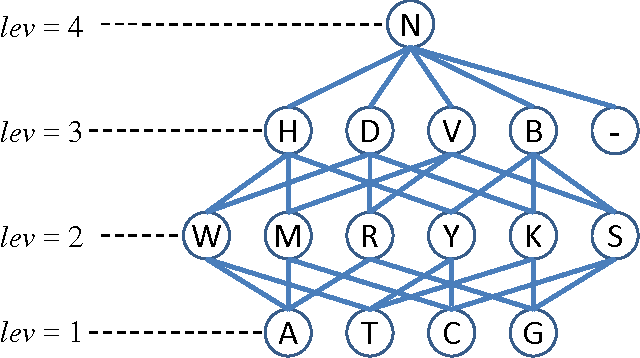
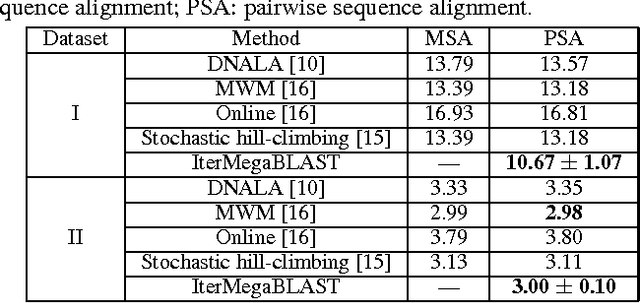
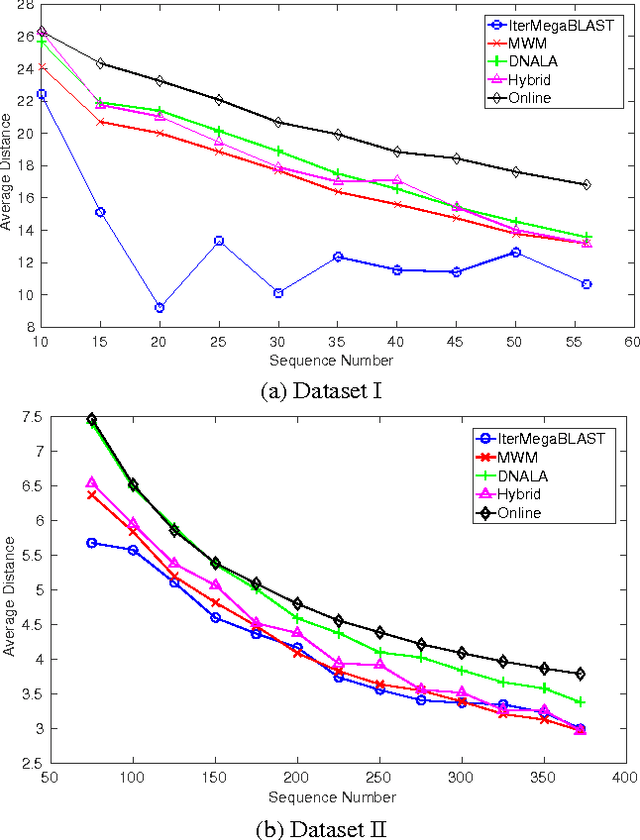

In the post-genomic era, large-scale personal DNA sequences are produced and collected for genetic medical diagnoses and new drug discovery, which, however, simultaneously poses serious challenges to the protection of personal genomic privacy. Existing genomic privacy-protection methods are either time-consuming or with low accuracy. To tackle these problems, this paper proposes a sequence similarity-based obfuscation method, namely IterMegaBLAST, for fast and reliable protection of personal genomic privacy. Specifically, given a randomly selected sequence from a dataset of DNA sequences, we first use MegaBLAST to find its most similar sequence from the dataset. These two aligned sequences form a cluster, for which an obfuscated sequence was generated via a DNA generalization lattice scheme. These procedures are iteratively performed until all of the sequences in the dataset are clustered and their obfuscated sequences are generated. Experimental results on two benchmark datasets demonstrate that under the same degree of anonymity, IterMegaBLAST significantly outperforms existing state-of-the-art approaches in terms of both utility accuracy and time complexity.