Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodic Event Recognition using Convolutional Neural Networks with Context Information
Paper and Code
Jun 02, 2017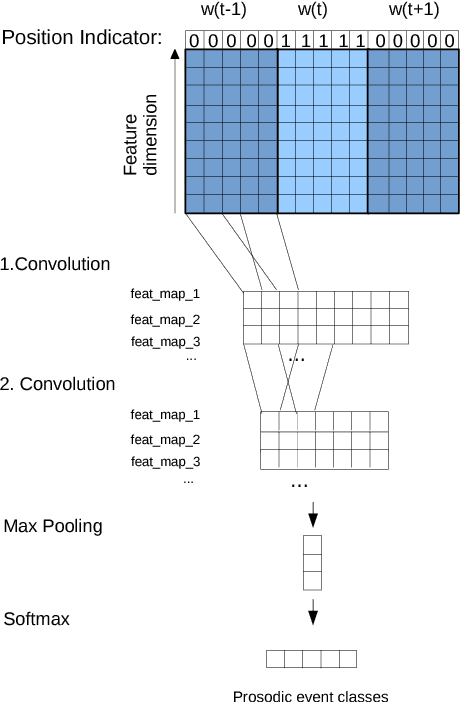
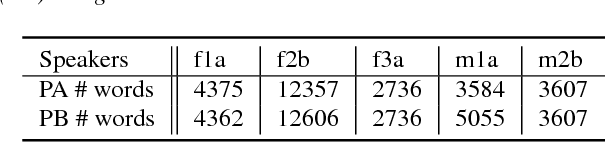

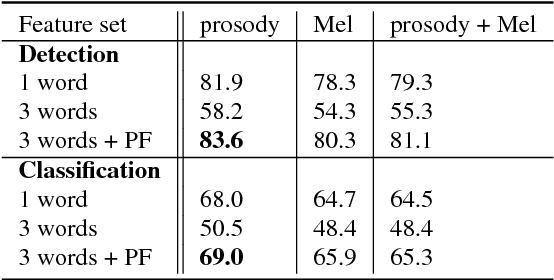
This paper demonstrates the potential of convolutional neural networks (CNN) for detecting and classifying prosodic events on words, specifically pitch accents and phrase boundary tones, from frame-based acoustic features. Typical approaches use not only feature representations of the word in question but also its surrounding context. We show that adding position features indicating the current word benefits the CNN. In addition, this paper discusses the generalization from a speaker-dependent modelling approach to a speaker-independent setup. The proposed method is simple and efficient and yields strong results not only in speaker-dependent but also speaker-independent cases.
* Interspeech 2017 4 pages, 1 figure
View paper on