 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjection-free Online Exp-concave Optimization
Paper and Code
Feb 09, 2023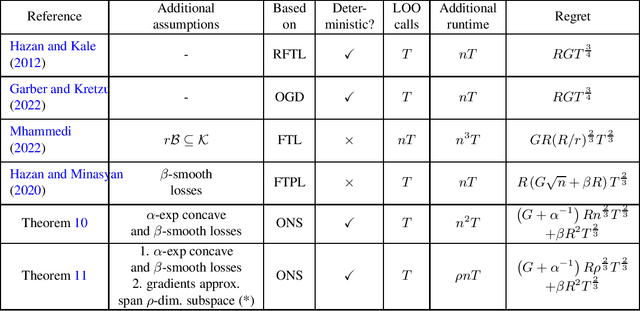
We consider the setting of online convex optimization (OCO) with \textit{exp-concave} losses. The best regret bound known for this setting is $O(n\log{}T)$, where $n$ is the dimension and $T$ is the number of prediction rounds (treating all other quantities as constants and assuming $T$ is sufficiently large), and is attainable via the well-known Online Newton Step algorithm (ONS). However, ONS requires on each iteration to compute a projection (according to some matrix-induced norm) onto the feasible convex set, which is often computationally prohibitive in high-dimensional settings and when the feasible set admits a non-trivial structure. In this work we consider projection-free online algorithms for exp-concave and smooth losses, where by projection-free we refer to algorithms that rely only on the availability of a linear optimization oracle (LOO) for the feasible set, which in many applications of interest admits much more efficient implementations than a projection oracle. We present an LOO-based ONS-style algorithm, which using overall $O(T)$ calls to a LOO, guarantees in worst case regret bounded by $\widetilde{O}(n^{2/3}T^{2/3})$ (ignoring all quantities except for $n,T$). However, our algorithm is most interesting in an important and plausible low-dimensional data scenario: if the gradients (approximately) span a subspace of dimension at most $\rho$, $\rho << n$, the regret bound improves to $\widetilde{O}(\rho^{2/3}T^{2/3})$, and by applying standard deterministic sketching techniques, both the space and average additional per-iteration runtime requirements are only $O(\rho{}n)$ (instead of $O(n^2)$). This improves upon recently proposed LOO-based algorithms for OCO which, while having the same state-of-the-art dependence on the horizon $T$, suffer from regret/oracle complexity that scales with $\sqrt{n}$ or worse.