 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling of OCR'ed Historical Texts Revisited
Paper and Code

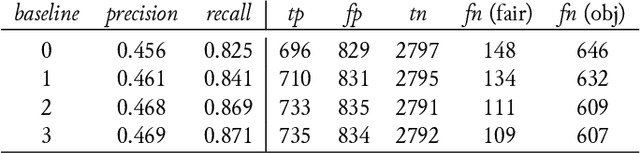

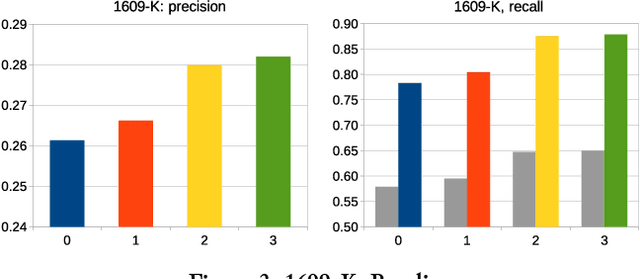
In the absence of ground truth it is not possible to automatically determine the exact spectrum and occurrences of OCR errors in an OCR'ed text. Yet, for interactive postcorrection of OCR'ed historical printings it is extremely useful to have a statistical profile available that provides an estimate of error classes with associated frequencies, and that points to conjectured errors and suspicious tokens. The method introduced in Reffle (2013) computes such a profile, combining lexica, pattern sets and advanced matching techniques in a specialized Expectation Maximization (EM) procedure. Here we improve this method in three respects: First, the method in Reffle (2013) is not adaptive: user feedback obtained by actual postcorrection steps cannot be used to compute refined profiles. We introduce a variant of the method that is open for adaptivity, taking correction steps of the user into account. This leads to higher precision with respect to recognition of erroneous OCR tokens. Second, during postcorrection often new historical patterns are found. We show that adding new historical patterns to the linguistic background resources leads to a second kind of improvement, enabling even higher precision by telling historical spellings apart from OCR errors. Third, the method in Reffle (2013) does not make any active use of tokens that cannot be interpreted in the underlying channel model. We show that adding these uninterpretable tokens to the set of conjectured errors leads to a significant improvement of the recall for error detection, at the same time improving precision.