Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcNet: Deep Predictive Coding Model for Robust-to-occlusion Visual Segmentation and Pose Estimation
Paper and Code



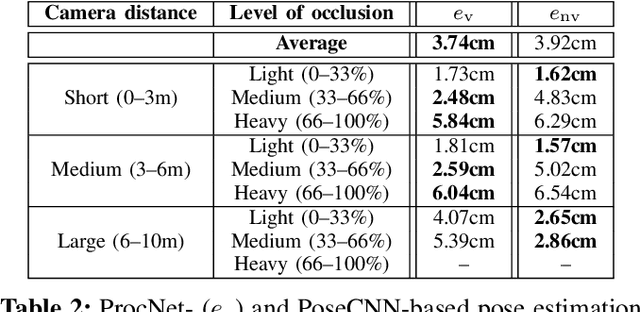
Systems involving human-robot collaboration necessarily require that steps be taken to ensure safety of the participating human. This is usually achievable if accurate, reliable estimates of the human's pose are available. In this paper, we present a deep Predictive Coding (PC) model supporting visual segmentation, which we extend to pursue pose estimation. The model is designed to offer robustness to the type of transient occlusion naturally occurring when human and robot are operating in close proximity to one another. Impact on performance of relevant model parameters is assessed, and comparison to an alternate pose estimation model (NVIDIA's PoseCNN) illustrates efficacy of the proposed approach.
* 7 pages, 9 figures
View paper on