 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Monitoring on Sequences of System Call Count Vectors
Paper and Code
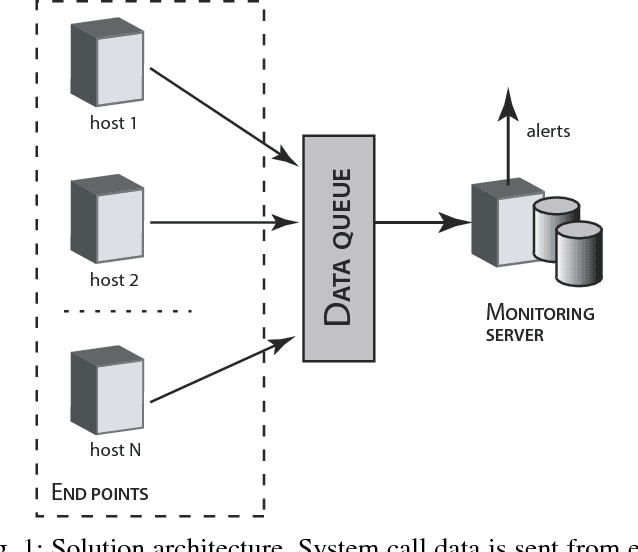
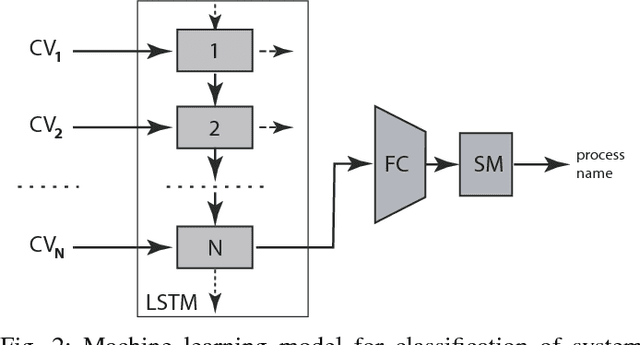
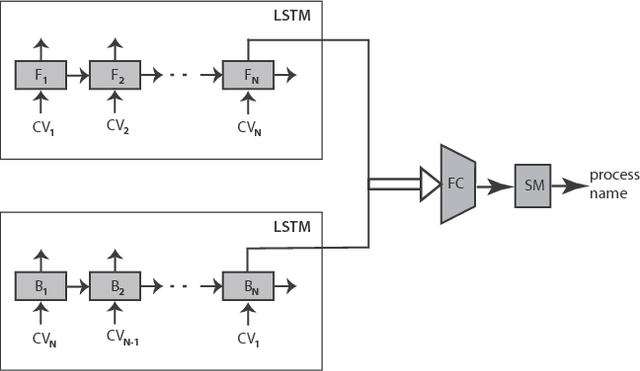
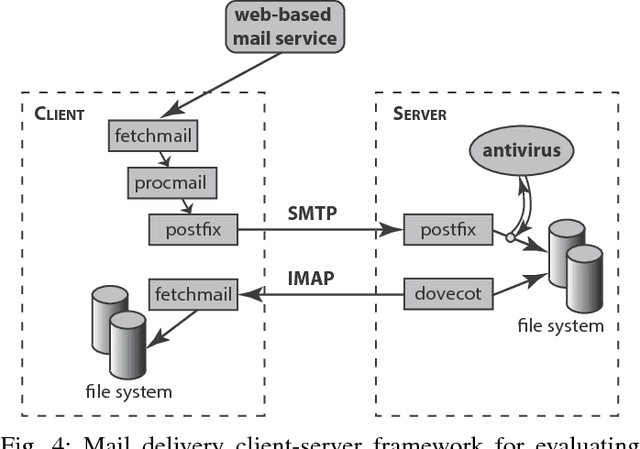
We introduce a methodology for efficient monitoring of processes running on hosts in a corporate network. The methodology is based on collecting streams of system calls produced by all or selected processes on the hosts, and sending them over the network to a monitoring server, where machine learning algorithms are used to identify changes in process behavior due to malicious activity, hardware failures, or software errors. The methodology uses a sequence of system call count vectors as the data format which can handle large and varying volumes of data. Unlike previous approaches, the methodology introduced in this paper is suitable for distributed collection and processing of data in large corporate networks. We evaluate the methodology both in a laboratory setting on a real-life setup and provide statistics characterizing performance and accuracy of the methodology.